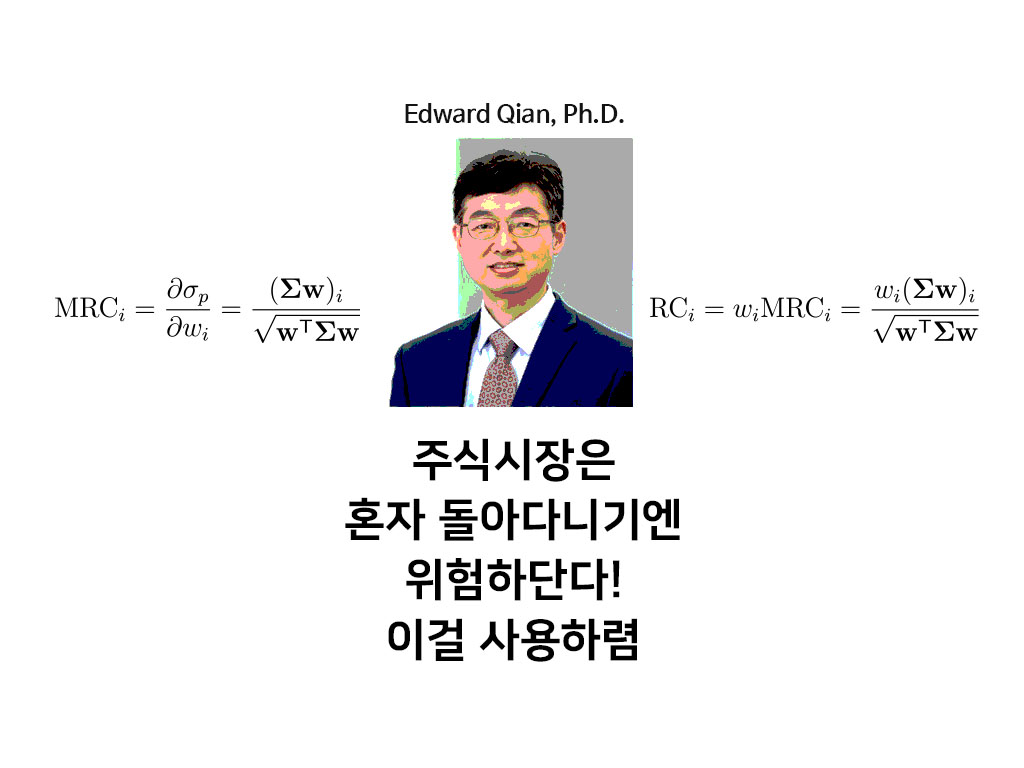
주식시장은 혼자 돌아다니기엔 위험하단다! 이걸 사용하렴: 리스크 패리티
리스크 패리티(Risk Parity)는 포트폴리오에 포함된 각 자산의 위험을 동일하게 맞추어 안정성과 수익률을 모두 추구하는 전략입니다.
2005년 Edward Qian의 Risk Parity Portfolios : Efficient Portfolios Through True Diversification에 의해 처음 제안된 리스크 패리티는,
각 자산(채권, 주식, 부동산 등)이 포트폴리오 전체 변동성에 동등하게 기여한다는 제약에 따라 최소-분산 포트폴리오를 생성하는 것과 유사합니다.
또한, 위험 계산을 위한 공분산 행렬만을 필요하기 때문에, 기대수익률 추정이 필요하지 않은 위험 기반 자산배분 모형입니다.
Inverse Volatility
Naive Risk Parity라고도 불리는 역 변동성(Inverse Volatility) 포트폴리오는 변동성의 역수만큼 각 자산의 투자 비중을 결정합니다.
따라서, 투자 비중 \(w\)는 아래와 같이 정의됩니다.
\[w_i=\frac{\frac{1}{\sigma_i}}{\sum_k{\frac{1}{\sigma_k}}}\quad\cdots(1)\]역 변동성 포트폴리오의 대표적인 사례로, 과거 유행했던 TQQQ와 TMF를 이용한 자산배분 전략이 있습니다.
참고: QQQ+TLT 세배 레버리지를 이용한 어퍼스 레버리지 전략 백테스팅
Equally-Weighted Risk Contribution(ERC)
일반적으로 리스크 패리티를 말하면, 동일 가중 위험 기여(ERC; Equally-Weighted Risk Contribution) 방식을 의미하곤 합니다.
대표적으로, 사계절(All Weather) 포트폴리오가 리스크 패리티에 기반하고 있다고 할 수 있습니다.
참고: 레이달리오의 ‘올 웨더 전략(All Weather Portfolio)’ 총정리
참고: Bridgewater가 말하는 Risk Parity(리스크 패러티) 上
동일 가중 위험 기여는 각 자산이 동일한 변동성을 가져야 하는 것이 아닌, 각 자산이 전체 포트폴리오의 변동성에 기여하는 정도를 동일하게 만드는 것을 말합니다.
여기서, 위험 기여도(RC; Risk Contribution)와 한계 위험 기여도(MRC; Marginal Risk Contribution)라는 개념이 나옵니다.
먼저 한계 위험 기여도(MRC)란 특정 자산의 비중(\(w\))을 한 단위 증가시켰을 때 전체 포트폴리오의 위험(\(\sigma_p\))의 증가를 나타내는 단위를 말합니다.
수학적으로는 아래와 같이 미분을 통해 정의됩니다.
\[\text{MRC}_i=\frac{\partial \sigma_p}{\partial w_i}=\frac{(\mathbf{\Sigma w})_i}{\sqrt{\mathbf{w}^\mathsf{T}\mathbf{\Sigma w}}}\]포트폴리오의 총 위험 \(\sigma_p\)는 아래와 같이 정의됩니다.
\[\sigma_p=\sqrt{\mathbf{w}^\mathsf{T}\mathbf{\Sigma w}}\]
한계 위험 기여도(MRC)에 투자 비중 \(w\)를 곱하면, 전체 포트폴리오의 위험에 기여하는 정도를 뜻하는 위험 기여도(RC)를 계산할 수 있습니다.
\[\text{RC}_i=w_i\text{MRC}_i=\frac{w_i(\mathbf{\Sigma w})_i}{\sqrt{\mathbf{w}^\mathsf{T}\mathbf{\Sigma w}}}\quad\cdots(2)\]위험 기여도를 전부 합하면 포트폴리오의 총 위험이 됩니다.
\[\sum{\text{RC}_i}=\frac{1}{\sqrt{\mathbf{w}^\mathsf{T}\mathbf{\Sigma w}}}\sum{w_i(\mathbf{\Sigma w})_i}\] \[=\frac{\mathbf{w}^\mathsf{T}\mathbf{\Sigma w}}{\sqrt{\mathbf{w}^\mathsf{T}\mathbf{\Sigma w}}}=\sqrt{\mathbf{w}^\mathsf{T}\mathbf{\Sigma w}}=\sigma_p\]
동일 가중 위험 기여는 \(\text{RC}_i\)를 모두 같게 만드는 것입니다.
또한, 위험 기여도의 합 \(\sum{\text{RC}_i}=\sigma_p\)이므로, 위험 기여도는 아래와 같습니다.
\[\text{RC}_i=\frac{\sigma_p}{n}\]역 변동성 전략의 유도
각 자산 간의 상관관계(\(\rho\))가 0이라고 가정합시다.
그렇다면, 공분산 행렬 \(\mathbf{\Sigma}\)은 대각 행렬(Diagonal Matrix)이 됩니다. (공분산 행렬의 정의)
이때, 투자 비중 \(w_i\)는 아래와 같습니다.
\[w_i=\frac{\frac{1}{\sigma_i}}{\sum_k{\frac{1}{\sigma_k}}}\]참고: Introduction to Risk Parity and Budgeting
즉, 자산 간의 상관관계가 0이라면, 동일 가중 위험 기여와 역 변동성 포트폴리오의 투자 비중은 동일합니다.
이것이 역 변동성 전략을 Naive Risk Parity라 부르는 이유입니다. (상관관계가 없는 자산 간의 리스크 패리티)
하지만, 만약 공분산 행렬 \(\mathbf{\Sigma}\)이 대각 행렬이 아니라면, 위와 같은 닫힌 형태의 해(Closed-form Solution)를 구할 수 없습니다.
현실에서 상관관계가 0인 자산은 거의 존재하지 않기 때문에, 이번에도 수치해석적인 방식을 통해 \(w_i\)를 구해야 합니다.
가장 대표적인 방식은 L2 norm을 최소화하여 \(w_i\)를 찾는 것입니다.
\[\min_{\mathbf{w}}{\sum_i{\sum_j{(\text{RC}_i-\text{RC}_i)^2}}}\] \[\text{s.t. }\mathbf{w}^\mathsf{T}\mathbf{1}=1\]모든 \(\text{RC}_i\)간의 차이를 제곱해서 더한 값이 최소가 되게 하면, \(\text{RC}_i\)는 하나의 숫자로 수렴하게 될 것입니다.
이론적으로는 0에 수렴할 때, 모든 \(\text{RC}_i\)가 같아집니다.
마치, 선형 회귀식에서 사용하는 최소 제곱 원칙(Least Squares Principle)을 가져와 적용했다고 생각하시면 됩니다.
참고: 이 직선… 내 점들이 다 담아질까…? 단순 선형 회귀식 유도와 R 프로그래밍
일단, 목적 함수를 좀 더 정리합시다.
\[\sum_i{\sum_j{(\text{RC}_i-\text{RC}_i)^2}}\] \[=\sum_i{\sum_j{(\frac{w_i(\mathbf{\Sigma w})_i}{\sqrt{\mathbf{w}^\mathsf{T}\mathbf{\Sigma w}}}-\frac{w_j(\mathbf{\Sigma w})_j}{\sqrt{\mathbf{w}^\mathsf{T}\mathbf{\Sigma w}}})^2}}\]\(\frac{1}{\sqrt{\mathbf{w}^\mathsf{T}\mathbf{\Sigma w}}}\)를 밖으로 빼면,
\[\min_{\mathbf{w}}{\frac{\sum_i{\sum_j{(w_i(\mathbf{\Sigma w})_i-w_j(\mathbf{\Sigma w})_j)^2}}}{\mathbf{w}^\mathsf{T}\mathbf{\Sigma w}}}\]이때, \(\frac{1}{\mathbf{w}^\mathsf{T}\mathbf{\Sigma w}}\)를 제거하더라도 목적 함수를 수렴시키는 데에는 영향을 미치지 않습니다.
따라서,
\[\min_{\mathbf{w}}{\sum_i{\sum_j{(w_i(\mathbf{\Sigma w})_i-w_j(\mathbf{\Sigma w})_j)^2}}}\quad\cdots(3)\] \[\text{s.t. }\mathbf{w}^\mathsf{T}\mathbf{1}=1\]실습
일반적으로 리스크 패리티를 사용할 때는 위험 구조가 다른 자산들을 이용해 포트폴리오를 구성해야 합니다.
이번에는 SPY(주식), TLT(장기 국채), IEF(중기 국채), GLD(금), USO(원유) 다섯 개 종목을 이용할 것입니다.
import yfinance as yf
tickers = ['SPY', 'TLT', 'IEF', 'GLD', 'USO']
df = yf.download(tickers)
prices = df["Adj Close"].dropna(how="all")
returns = prices.pct_change().dropna(how="all")
returns_5y = returns[-(252*5+1):-1]
공분산 행렬을 만듭니다.
Sigma = returns_5y.cov() * 252
| GLD | IEF | SPY | TLT | USO | |
|---|---|---|---|---|---|
| GLD | 0.022297 | 0.004635 | 0.003216 | 0.008155 | 0.004949 |
| IEF | 0.004635 | 0.006000 | -0.002168 | 0.012397 | -0.005266 |
| SPY | 0.003216 | -0.002168 | 0.044922 | -0.007367 | 0.030374 |
| TLT | 0.008155 | 0.012397 | -0.007367 | 0.031031 | -0.013655 |
| USO | 0.004949 | -0.005266 | 0.030374 | -0.013655 | 0.198475 |
공분산 행렬을 NumPy의 행렬 타입으로 변환합니다. (원활한 행렬 계산을 위해서 타입 변환이 필요합니다)
import numpy as np
Sigma = np.array(Sigma)
[[ 0.02229725 0.00463468 0.0032155 0.00815494 0.00494932]
[ 0.00463468 0.00600049 -0.00216773 0.01239737 -0.00526561]
[ 0.0032155 -0.00216773 0.04492164 -0.00736703 0.0303741 ]
[ 0.00815494 0.01239737 -0.00736703 0.03103117 -0.01365536]
[ 0.00494932 -0.00526561 0.0303741 -0.01365536 0.19847481]]
이제, scipy.optimize.minimize 함수를 이용해서 투자 비중 w를 찾아줍니다.
초깃값 설정:
SLSQP 알고리즘은 초깃값을 어떻게 설정하느냐에 따라 결과가 달라질 수 있기 때문에, 최적의 값과 가까운 역 변동성의 투자 비중을 초깃값으로 설정합니다.
참고: 파이썬 scipy 이용한 최적화(Optimization) 예시
\[w_i=\frac{\frac{1}{\sigma_i}}{\sum_k{\frac{1}{\sigma_k}}}\quad\cdots(1)\]import math
w = np.array([(1 / math.sqrt(Sigma[i][i])) for i in range(len(Sigma))])
w = w / w.sum()
목적 함수 정의:
\[\sum_i{\sum_j{(w_i(\mathbf{\Sigma w})_i-w_j(\mathbf{\Sigma w})_j)^2}}\quad\cdots(3)\]def l2_norm(w1):
w1 = w1.reshape((-1, 1)) # vector to matrix
RC = w1 * (Sigma @ w1)
return np.sum((RC - RC.T)**2)
w1도 Vector 타입이기 때문에 직접 Matrix 타입으로 변환해야 합니다. (행렬 곱을 위한 크기 맞추기)
.reshape((-1, 1))은 \(n\times 1\) 행렬로의 변환을 의미합니다.
NumPy 코딩 트릭
\(\sum{\sum{(w_i(\mathbf{\Sigma w})_i-w_j(\mathbf{\Sigma w})_j)^2}}\)은 모든 \(w(\mathbf{\Sigma w})\) 원소간 크기 차의 합을 의미합니다.
여기서 \(RC=w(\mathbf{\Sigma w})\)는 \(n\times 1\) 행렬로 표현됩니다.
한 가지 예를 들어보겠습니다.
a = np.array([0, 1, 2]).reshape((-1, 1))
a는 \(3\times 1\) 행렬입니다.벡터와 다르게, 행렬은
a - a.T연산에 대해 다른 동작을 보입니다.[[0 1 2] [[0 0 0] [[0 1 2] [0 1 2] - [1 1 1] = [1 0 1] [0 1 2]] [2 2 2]] [2 1 0]]행렬 크기를 강제로 맞춰주는 과정에서 각 원소의 차가 담겨있는 행렬이 생성됩니다.
아래는 \(\sum{\sum{(a_i-a_j)^2}}\)를 표현한 코드입니다.
d = (a - a.T) ** 2 print(d) print(d.sum())[[0 1 4] [1 0 1] [4 1 0]] 12
최적화:
인자로 l2_norm 함수와 초깃값이 들어있는 w를 전달합니다.
res = minimize(l2_norm, w, method='SLSQP', constraints=[
{'type': 'eq', 'fun': lambda w: w.sum() - 1}, # sum(w) - 1 = 0
{'type': 'ineq', 'fun': lambda w: w}, # w >= 0
], tol=1e-20)
message: Optimization terminated successfully
success: True
status: 0
fun: 6.935296458545345e-19
x: [ 1.928e-01 3.653e-01 1.783e-01 1.780e-01 8.561e-02]
nit: 36
jac: [ 2.856e-11 2.952e-11 2.836e-11 2.948e-11 3.176e-11]
nfev: 216
njev: 36
tol은 최적화에서 허용 오차를 의미하는 옵션인데, 1e-20과 같이 매우 작은 숫자를 지정하길 권장합니다.
투자 비중 w1이 0.1 수준(10%)인 데다, RC를 계산하는 과정에서 w와 Sigma를 곱하게 되어 숫자가 계속 작아집니다.
마지막으로, RC를 제곱(1 미만의 수를 제곱하면 더 작아짐)해 출력하기 때문에 l2_norm의 출력값은 매우 작은 숫자가 나옵니다.
따라서, tol이 충분히 작지 않으면 완전히 최적화되지 않은 값이 나오기 때문에, 1e-20 수준의 매우 작은 숫자를 설정해야 합니다.
투자 비중 제약조건은,
{'type': 'ineq', 'fun': lambda w: 0.3 - w}, # w <= 0.3형태로
constraints에 추가하면 됩니다.
참고: scipy.optimize.minimize - SciPy
결과 확인:
w = res.x
[0.1927974 0.36528323 0.17830124 0.17800539 0.08561274]
최적화된 투자 비중은,
SPY(주식): 17.8%TLT(장기 국채): 17.8%IEF(중기 국채): 36.5%GLD(금): 19.2%USO(원유): 8.6%
입니다.
이때의 위험 기여도(RC)는,
\[\text{RC}_i=\frac{w_i(\mathbf{\Sigma w})_i}{\sqrt{\mathbf{w}^\mathsf{T}\mathbf{\Sigma w}}}\quad\cdots(2)\]RC = w * (Sigma @ w) / math.sqrt(w.T @ Sigma @ w)
[0.01804055 0.01804055 0.01804055 0.01804055 0.01804055]
0.01804로 모두 동일한 값이 나오는 것을 확인할 수 있습니다.