
Rust: Criterion.rs를 이용한 알고리즘 성능 측정
Criterion.rs은 통계 기반 벤치마킹 도구입니다.
Criterion.rs는 벤치마크 실행 간에 통계 정보를 저장하며 성능 향상을 자동으로 감지할 수 있습니다.
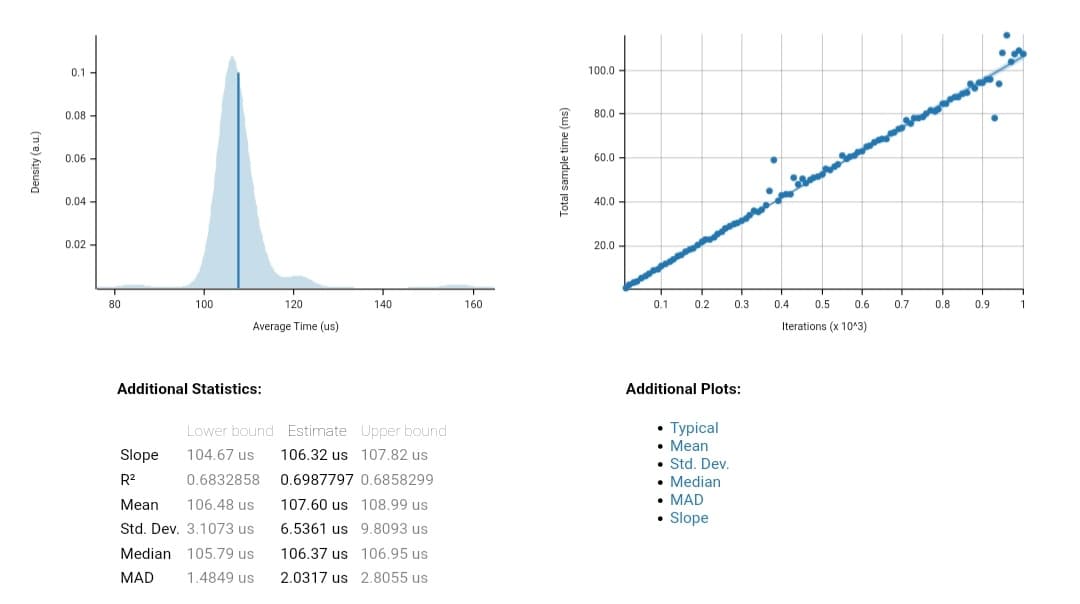
Criterion.rs 통계 보고서
스크린샷과 같이 알고리즘의 실행 시간을 PDF(Probability Density Function) 그래프로 보여주고, 그 밑에 자세한 통계적 수치를 표시합니다.
오른쪽 그래프는 회귀 그래프로, 반복 횟수 대 소요 시간을 보여주는 X-Y 평면에 그려진 각 데이터 포인트를 보여줍니다.
회귀 그래프
좋은 벤치마크는 데이터가 모두 직선에 밀접하게 표시됩니다. 데이터가 광범위하게 흩어져 있으면 데이터에 노이즈가 많고 벤치마크가 신뢰할 수 없음을 의미합니다.
설치
Cargo.toml:
[dev-dependencies]
criterion = "0.3"
[[bench]]
name = "benchmark_main"
harness = false
harness = false는 libtest의 harness를 비활성화하고, 벤치마크 코드에서 main 함수를 사용할 수 있도록 합니다.
참고: cargo bench
코드 작성
benches/benchmark_main.rs:
use criterion::{black_box, criterion_group, criterion_main, Criterion};
fn fibonacci(n: u64) -> u64 {
match n {
0 => 1,
1 => 1,
n => fibonacci(n-1) + fibonacci(n-2),
}
}
fn criterion_benchmark(c: &mut Criterion) {
c.bench_function("fib 20", |b| b.iter(|| fibonacci(black_box(20))));
}
criterion_group!(benches, criterion_benchmark);
criterion_main!(benches);
fibonacci 함수의 실행 시간을 측정하는 코드입니다.
criterion_main과 criterion_group으로 실행할 벤치마크 함수를 지정합니다.
criterion_benchmark 함수의 인자 c: &mut Criterion의 bench_function를 이용해 함수의 실행 시간을 측정합니다.
black_box는 컴파일러 최적화를 막아, 컴파일러에 의해 알고리즘 자체가 변형되는 것을 방지하기 위해 사용합니다.
매개변수 벤치마킹
benches/benchmark_main.rs:
use criterion::{criterion_group, criterion_main, BenchmarkId, Criterion};
fn do_something(size: usize) {
// Do something with the size
}
fn criterion_benchmark(c: &mut Criterion) {
let size: usize = 1024;
c.bench_with_input(BenchmarkId::new("input_example", size), &size,
|b, &s| b.iter(|| do_something(s)));
}
criterion_group!(benches, criterion_benchmark);
criterion_main!(benches);
BenchmarkId::new를 이용해 매개변수가 포함된 벤치마크 이름을 지정할 수 있습니다.
BenchmarkId::from_parameter를 이용하면 매개변수 자체를 벤치마크 이름으로 사용할 수 있습니다.
벤치마크 비교
benches/benchmark_main.rs:
use criterion::{criterion_group, criterion_main, BenchmarkId, Criterion};
fn fibonacci_slow(n: u64) -> u64 {
match n {
0 => 1,
1 => 1,
n => fibonacci_slow(n-1) + fibonacci_slow(n-2),
}
}
fn fibonacci_fast(n: u64) -> u64 {
let mut a = 0;
let mut b = 1;
match n {
0 => b,
_ => {
for _ in 0..n {
let c = a + b;
a = b;
b = c;
}
b
}
}
}
fn criterion_benchmark(c: &mut Criterion) {
let mut group = c.benchmark_group("Fibonacci");
for i in [20u64, 21u64].iter() {
group.bench_with_input(BenchmarkId::new("Recursive", i), i,
|b, i| b.iter(|| fibonacci_slow(*i)));
group.bench_with_input(BenchmarkId::new("Iterative", i), i,
|b, i| b.iter(|| fibonacci_fast(*i)));
}
group.finish();
}
criterion_group!(benches, criterion_benchmark);
criterion_main!(benches);
benchmark_group를 이용하면 벤치마크 집합을 만들어, 집합 간의 알고리즘 성능 차이를 비교할 수 있습니다.

qp-postgres 벤치마크
벤치마크 집합의 성능은 위와 같이 바이올린 그래프 형태로 표현됩니다.
벤치마크 세부 설정
let mut group = c.benchmark_group("group");
group
.measurement_time(Duration::from_secs(5))
.nresamples(10_000)
.sample_size(100)
.sampling_mode(SamplingMode::Linear)
.warm_up_time(Duration::from_millis(100));
Criterion.rs는 다양한 벤치마크 설정을 지원하지만, 벤치마크 속도와 정확도에 영향을 주는 5가지 지표만 알아보겠습니다.
measurement_time은 한 함수에 사용할 벤치마크 측정 시간을 의미합니다.
더 오래 함수를 실행할수록, 측정 횟수가 늘어나 외부 노이즈가 줄어들게 됩니다.
nresamples은 재추출(resample) 횟수를 의미합니다.
재추출 횟수가 많을수록 부트스트랩 방식의 무작위 표본 추출 오류가 줄어들지만 분석 시간도 늘어납니다.
참고: resampling을 이용한 방법 (bootstrapping)
sample_size는 표본의 크기를 의미합니다.
충분한 측정 시간이 주어졌을 경우, 표본의 크기가 클수록 더 정확한 결과가 나옵니다.
최소 크기는 10입니다.
sampling_mode는 표본 추출 방식을 의미합니다.
-
AutoCriterion.rs는 기본적으로 표본 추출 방법을 자동으로 선택합니다. 대부분의 사용자와 벤치마크에 이 모드를 사용할 것을 권장합니다. -
Linear각 표본의 반복 횟수를 선형으로 증가시킵니다. 대부분의 벤치마크에 적합하지만 매우 긴 벤치마크의 경우 속도가 매우 느려질 수 있습니다. -
Flat모든 표본을 동일한 반복 횟수로 측정합니다. 벤치마크 통계에 영향을 미치므로 권장하지 않지만, 선형 방법보다 반복 횟수가 적기 때문에 정확도보다 벤치마크 실행 시간이 더 중요한 매우 오래 걸되는 벤치마크에 더 적합합니다.
warm_up_time은 벤치마크 측정 전 함수를 미리 실행할 시간입니다.
JIT, 캐시 등이 함수의 성능에 미치는 영향이 큰 경우, 길게 설정하는 것을 권장합니다.
참고: Criterion.rs Advanced Configuration
벤치마크 반복 함수
벤치마크 반복 함수는 크게 2가지 있습니다.
iter는 위 코드에서 사용한 것과 같이 기본적인 반복 함수입니다.
iter_custom은 사용자가 반복 함수를 직접 구현할 때 사용합니다.
b.iter_custom(|iters| async move {
let pool = Pool::new(IntFactory, input.0);
pool.reserve(input.0);
let start = Instant::now();
for _ in 0..iters {
let handles = (0..input.1)
.map(|_| {
let pool = pool.clone();
tokio::spawn(async move {
let int = pool.acquire().await.unwrap();
loop_factorial20();
criterion::black_box(*int);
})
})
.collect::<Vec<_>>();
for handle in handles {
handle.await.unwrap();
}
}
start.elapsed()
})
위 코드처럼 함수를 초기화하고 리소스를 예약하는 과정이 측정 시간에 포함되면 안되는 경우에는 반복 함수를 직접 구현해야 합니다.
iter_custom은 iters를 제공하는 함수를 입력 받으며, Instant::elapsed를 이용해 실행 시간을 측정하게 구현하면 됩니다.
이 밖에도 iter_with_large_drop 등의 반복 함수가 있지만, 아래 문서를 참고하시길 바랍니다.
비동기 함수 벤치마크
to_async 함수를 이용하면 비동기 함수도 실행 시간을 측정할 수 있습니다.
use tokio::runtime::Runtime;
b.to_async(Runtime::new().unwrap())
Tokio의 경우 Runtime을 바로 사용하면 되고,
async-std, smol 등은 criterion::async_executor에서 제공하는 구조체를 사용하면 됩니다.
| Runtime | Feature | Executor |
|---|---|---|
| Tokio | async_tokio | tokio::runtime::Runtime |
| async-std | async_std | AsyncStdExecutor |
| Smol | async_smol | SmolExecutor |
| futures | async_futures | FuturesExecutor |
비동기 함수를 사용하는 경우,
Cargo.toml에서features를 활성화 해야합니다.