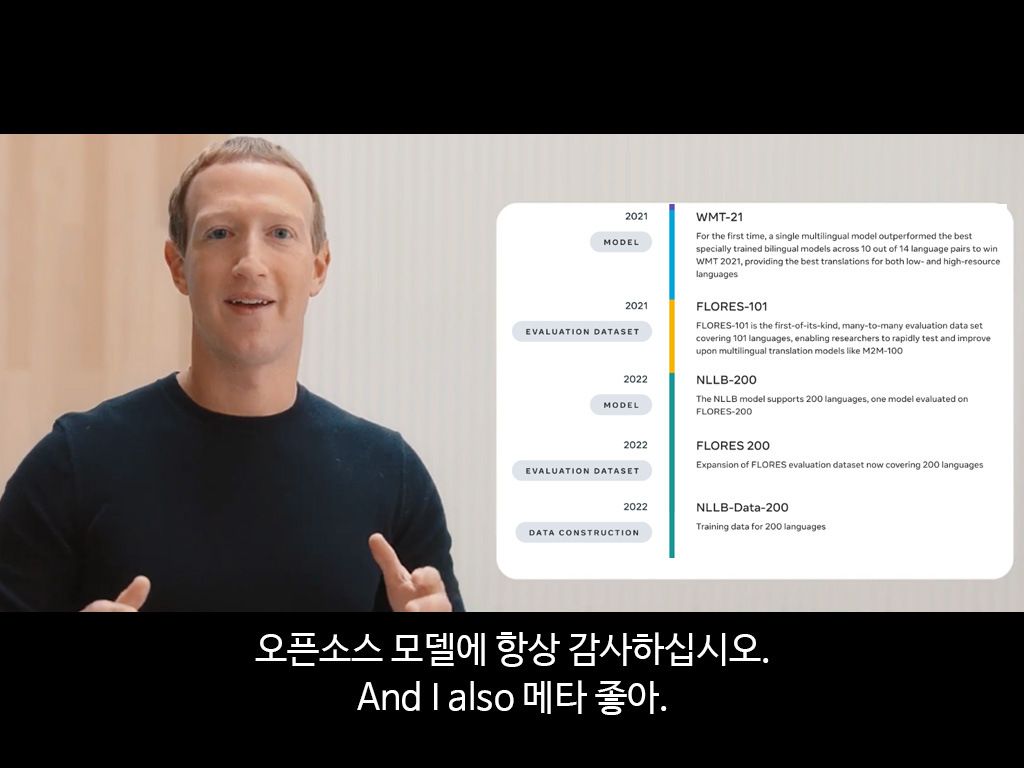
Meta에 항상 감사하십시오. NLLB-200 모델을 이용한 기계번역
NLLB-200은 Meta에서 개발한 다국어 번역 모델입니다.
제공하는 모델의 크기는 600M, 1.3B, 3.3B가 있고 이 중 600M과 1.3B는 경량화(Distilled)된 모델입니다.
참고: 딥러닝 Knowledge Distillation
아스투리아스어, 루간다어, 우르두어 등 리소스가 적은 언어를 포함하여 200개 언어 간의 번역을 제공할 수 있는 오픈소스 모델이며, 한국어도 당연히 포함되어 있습니다.
하지만, 연구 목적으로 배포된 모델이기 때문에 프로덕션용으로 사용하기 어려운 단점이 있습니다.
HuggingFace Pipeline
NLLB 모델을 이용하는 가장 간편한 방법은 HuggingFace의 Pipeline을 이용하는 것입니다.
HuggingFace의 Pipeline은 모델에서의 전처리, 후처리, 추론과정을 묶어 하나의 함수로 제공하는 기능입니다.
Pipeline을 사용하기 위해서는 torch와 transformers가 필요합니다.
$ pip3 install torch --index-url https://download.pytorch.org/whl/cu118
$ pip install transformers
Conda를 이용하는 경우 아래 명령어로 설치할 수 있습니다.
conda install pytorch pytorch-cuda=11.8 -c pytorch -c nvidia conda install -c huggingface transformers
먼저 가장 용량이 작은 600M 모델로 영어->한국어 번역을 해보겠습니다.
모델을 돌리기 위해서는 3GB 정도의 VRAM이 필요합니다.
from transformers import pipeline
translator = pipeline('translation', model='facebook/nllb-200-distilled-600M', device=0, src_lang='eng_Latn', tgt_lang='kor_Hang', max_length=512)
device=0으로 설정한 이유는 CPU가 아니라 GPU를 이용해서 모델을 실행시키기 위함입니다.
입력 언어는 영어이므로 src_lang(source language)은 eng_Latn(English Latin)으로 지정하고, 출력 언어는 한국어이므로 tgt_lang(target language)는 kor_Hang(Korean Hangul)로 설정합니다.
nllb-200-distilled-600M 모델은 512 토큰 이하의 데이터셋으로 학습되었기 때문에 이것보다 더 긴 내용의 입력이 들어오면 번역 품질이 저하될 수 있습니다.
실행은 아래와 같이 하면 됩니다.
text = 'Lockheed Martin Delivers Initial 5G Testbed To U.S. Marine Corps And Begins Mobile Network Experimentation'
output = translator(text, max_length=512)
print(output[0]['translation_text'])
로크히드 마틴은 미국 해병대에 첫 번째 5G 테스트 베드를 공급하고 모바일 네트워크 실험을 시작했습니다
번역이 자연스럽지 않다면, 더 큰 모델(1.3B, 3.3B)을 이용해서 테스트해보세요. 일반적으로 모델의 사이즈가 클수록 번역이 자연스러워지지만 많은 리소스를 사용합니다.
Fine-tuned Model
NLLB는 범용적인 번역 모델이기 때문에 뜻이 대충 통하는 문장을 생성할 뿐, 자연스러운 문장을 생성하기엔 어려움이 있습니다.
그렇기에 자연스러운 영어->한국어 번역을 위해서는 한국어 데이터셋으로 Fine-tuning하여 모델의 성능을 끌어올려야 합니다.
Fine-tuning이란 기존의 학습된 모델을 새로운 목적의 맞게 재학습시키는 것을 말합니다.
정석대로라면 직접 한국어 데이터셋을 구해서 모델을 Fine-tuning 해야 하지만, 다행히 누군가 이미 한국어 데이터셋으로 훈련시켜 둔 모델을 찾을 수 있었습니다.
nllb-finetuned-en2ko는 facebook/nllb-200-distilled-600M을 기반으로 한 영어->한국어 번역 특화 모델입니다.
해당 모델은 AI-Hub에서 구한 한국어 데이터셋으로 Fine-tuning 되었고 CC-BY-4.0로 공개되었습니다.
사용방법은 NLLB와 동일합니다.
translator = pipeline('translation', model='NHNDQ/nllb-finetuned-en2ko', device=0, src_lang='eng_Latn', tgt_lang='kor_Hang', max_length=512)
text = 'Lockheed Martin Delivers Initial 5G Testbed To U.S. Marine Corps And Begins Mobile Network Experimentation'
output = translator(text, max_length=512)
print(output[0]['translation_text'])
록히드마틴이 미국 해병대에 최초 5G 테스트베드를 전달하고 모바일 네트워크 실험에 나선다
아까보다 더 자연스러운 문장이 생성된 것 같습니다.
HuggingFace Models
HuggingFace에서 다양한 한국어 번역 모델을 찾아볼 수 있습니다.
주의할 점은, en-ko 모델은 영어를 한국어로 번역하는 모델이고, ko-en 모델은 한국어를 영어로 번역하는 모델이란 점입니다.
모델을 평가하는 지표로는 BLEU Score가 있습니다.
BLEU Score(Bilingual Evaluation Understudy Score)는 n-gram을 이용해 기계 번역 결과와 사람이 직접 번역한 결과가 얼마나 유사한지 비교하여 번역에 대한 성능을 측정하는 방법입니다.
Score가 높을수록 더 좋은 성능을 보여주는 모델이라는 의미입니다.

위의 nllb-finetuned-en2ko의 BLUE Score는 33.66으로 NLLB-200 3.3B(Baseline)의 BLUE가 33.45인 것을 고려하면 Fine-tuning을 통해 더 적은 용량으로 높은 성능을 달성했다는 것을 확인할 수 있습니다.
위 그림에서 37.84점을 기록한 NLLB-200은 54B 크기의 MoE(Mixture-of-Experts) 모델입니다.