
[논문 리뷰] 들린다... 닿지 않았던 데이터셋의 목소리가... A Few Useful Things to Know about Machine Learning
ChatGPT로 인해 다시금 AI 시장에 대한 관심이 뜨겁습니다.
인공지능에 대해 이토록 관심을 가지는 사람이 많아진 건, 2016년 알파고 이후로 정말 오랜만인 것 같네요.
현재 AI 기술의 핵심을 이루는 것은 딥러닝(Deep learning)입니다.
그리고 딥러닝은 머신러닝(Machine learning)의 한 분류죠.
요즘 딥러닝을 공부 해보는 사람이 늘어나는 것 같습니다.
저도 개인적으로 계속 딥러닝을 공부 중인데,
프로젝트를 할 때마다,
- 논문에서 모델 가져와서
- 데이터 넣고
- 정확도 높게 나오는 파라미터 찍어 맞추기
같이, 인디언식 기우제 느낌으로 진행되는 것 같더라고요.
그래서 이번에는 머신러닝의 기본기에 대한 논문을 가져왔습니다.

논문 이름은 A Few Useful Things to Know about Machine Learning입니다.

저자 소개를 빼놓을 수 없는데요.
페드로 도밍고스(Pedro Domingos) 교수님은 국내에서는 마스터 알고리즘의 저자로 널리 알려진 분입니다.

Introduction에서는 앞으로 더 많은 곳에 머신러닝이 적용될 건데,
folk knowledge 없이 프로젝트가 진행되는 게 너무 많이 보인다는 말을 하고 있습니다.
근본없이 개발된 제 프로젝트 같아서 좀 찔리네요

Learning은 Representation, Evaluation, Optimization으로 구분될 수 있습니다.
대부분의 교재에서는 Representation, 모델이 어떻게 생겼는지를 중심으로 설명하는데,
저자는 Evaluation과 Optimization도 Representation 못지않게 중요하다는 것을 강조하고 있습니다.

머신러닝의 본질은 데이터의 일반화입니다.
이게 당연한 말인데, 예를 들어 고양이 품종을 분류하는 모델에서 학습 했던 사진이 실제 서비스에서 그대로 들어올 확률이 몇 %나 있을까를 생각해 보면 1% 채도 안 된다고 말할 수 있습니다.
그렇기에 데이터를 외우는 것이 아닌, 데이터의 패턴을 외우는 일반화가 가장 중요한 것입니다.
만약 Training dataset과 Test dataset를 쪼갤 만큼 데이터가 많지 않다면 Cross-validation을 고려할 수 있습니다.
Flexible한 분류기란 데이터의 미세한 패턴을 더 잘 받아들이는, 즉, 데이터를 잘 외울 수 있는 모델을 말합니다.

하지만, Training dataset이 많다고 일반화가 무조건 잘되는 것은 아닙니다.
Dataset에 맞는 올바른 모델을 선택하는 것도 중요합니다.
그렇기에 최적의 모델을 선택하기 위해선 데이터 도메인(금융 시계열, 날씨 항공사진 등)에 대한 연구도 병행되어야 합니다.

과적합(Over fitting)은 모델이 데이터를 일반화하지 못하고, 데이터를 그대로 외워버린 상태를 의미합니다.
Training dataset과 Test dataset의 정확도 차이가 크면 과적합을 의심해 볼 수 있습니다.
과적합은 Dataset의 크기가 작고, 다양하지 않을수록 잘 일어나고,
과적합을 방지하는 방법으로는 Cross-validation, 평가함수 정규화(Regularization), 데이터셋 점검(통계적 특성 확인) 등이 있습니다.

차원의 저주(curse of dimensionality)는 모델이 복잡해질수록(=파라미터가 많아질수록) 학습이 어려워지는 특성을 말합니다.
예를 들어, 데이터가 100개 밖에 없는데 모델 저장용량이 1000이라면,
모델은 데이터에서 패턴을 뽑아내 저장하는 게 아니라 데이터를 그대로 외워버리게 됩니다.
또한, 대부분의 모델에서 사용하는 유사성 기반(similarity-based)의 추론은 고차원에서 성능이 나빠지는 특성이 있습니다.
그렇기에 모델의 용량(Capacity)을 올리기 위해 무작정 차원을 늘리면 오히려 단점에 더 노출되게 됩니다.

논문에서는 복잡한 수학을 통한 이론적 보증이 등장하는데, 항상 이것들이 옳다고는 볼 수 없습니다.
머신러닝은 귀납법의 공학적 구현입니다.
입력될 수 있는 모든 경우의 수에서 일부인 학습 데이터(입력)를 통해 패턴을 학습하고,
출력으로 무수히 많은 결과를 뽑아낼 수 있기에 귀납법이라고 할 수 있습니다.
따라서 이론적 보증이 있다고 해서 항상 결론이 옳다고 보기는 어렵습니다.

머신러닝 모델의 성능은 어떤 데이터를 입력하는지에 굉장히 의존적입니다.
그렇기에 원시 데이터를 학습에 용이하도록 가공해야 합니다.
원시 데이터를 가공하는 방법 중 대표적인 것이 Feature Engineering입니다.
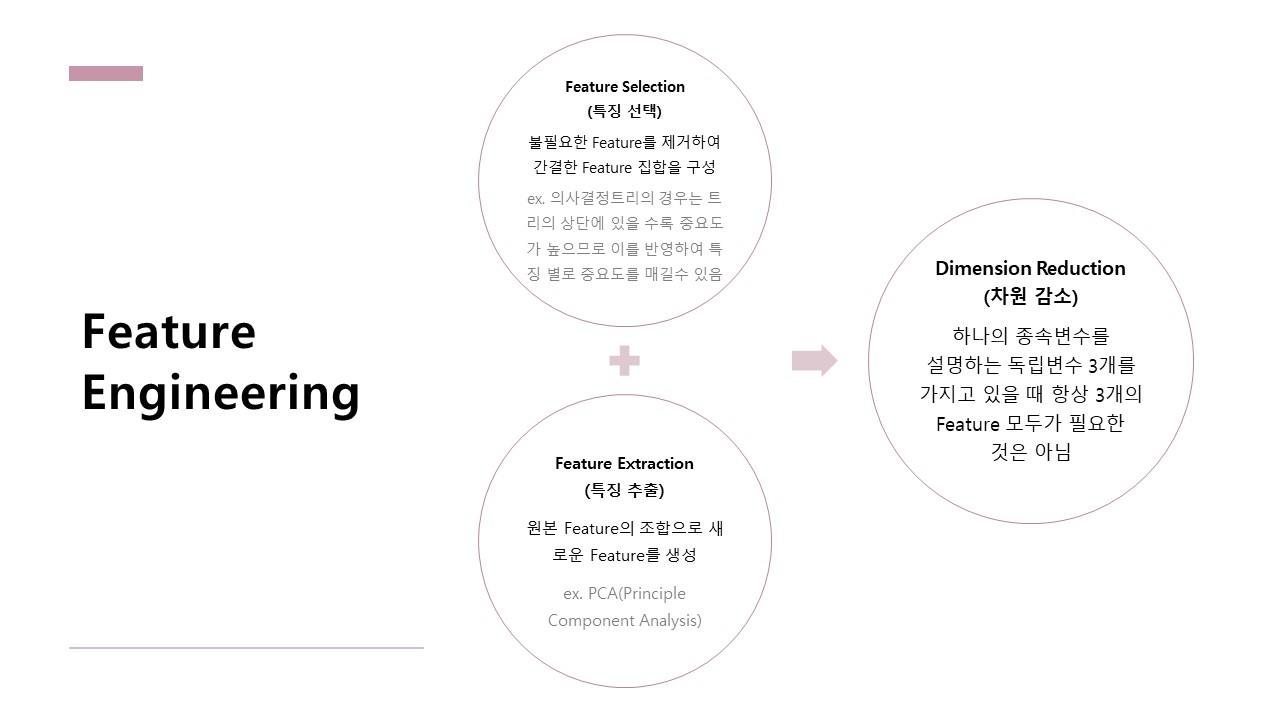
Feature Engineering의 주목표는 Dimension Reduction(차원 감소)입니다.
Dimension Reduction은 크게 Feature Selection과 Feature Extraction 두 분류로 나뉩니다.
Feature Selection은 중요한 Feature만 선택하여 모델에 집어넣는 것입니다.
예를 들어, 비만 환자 분류를 위한 모델일 경우, 이름, 성별, 나이, 키, 몸무게 등에서 키와 몸무게만 선택하여 학습 데이터셋을 만들고 모델에 학습시키는 것을 말합니다.
Feature Extraction은 기존의 Feature를 가공해 새로운 Feature를 만드는 것입니다.
비만 환자 분류를 위한 모델일 경우, 키와 몸무게 Feature를 조합해 BMI라는 Feature를 새로 만드는 것을 Feature Extraction이라고 볼 수 있습니다.

분류기의 성능을 올리는 방법은 2가지가 존재하는데, 현실적으로 성공률이 가장 높은 방법은 더 많은 데이터를 모으는 것입니다.
ML에서 가장 큰 병목(Bottleneck)은 데이터나 CPU가 아니라 사람이라는 말이 가장 인상적이었는데,
사람이 데이터 확보, 인사이트 추출 등의 노력을 기울일수록 성능이 더 올라갈 수 있다는 말을 전하고 있습니다. 반성해야겠네요
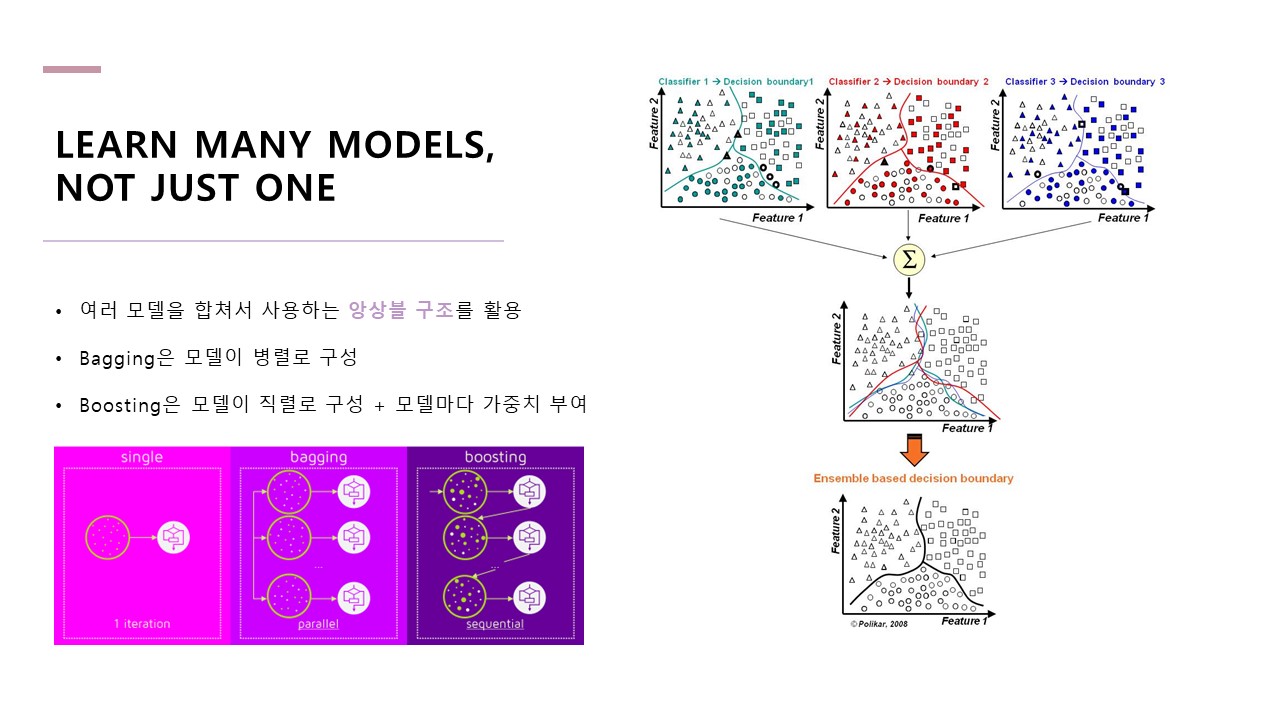
여러 모델을 합쳐서 사용하는 앙상블 구조를 활용할 것을 제안하고 있습니다.
앙상블은 Bagging과 Boosting, 두 가지의 형태가 있는데,
Bagging은 모델을 병렬로 구성하는 것을 말하고, Boosting은 모델을 직렬로 구성하는 것을 말합니다.
Boosting의 대표적인 사례가 XGBoost입니다.

경제학 원리 중 오컴의 면도날 원칙이라고 불리는 것이 있습니다.
단순함의 원칙이라고도 불리는 이 원칙은, 쓸데없이 복잡하게 만들지 말라는 뜻으로 해석되는데,
앞서 앙상블 모델에서 보셨다시피 머신러닝에는 적용되기 어렵습니다.
앙상블을 적용하면 0.1%씩이라도 정확도가 올라가기에 다양한 모델을 조합해 사용하는 것이 효과적입니다.
우리가 단순함을 추구하는 이유는 단순함이 정확성을 의미하기 때문이 아니라, 단순함이 보기 좋고 이해하기 쉽기 때문입니다.
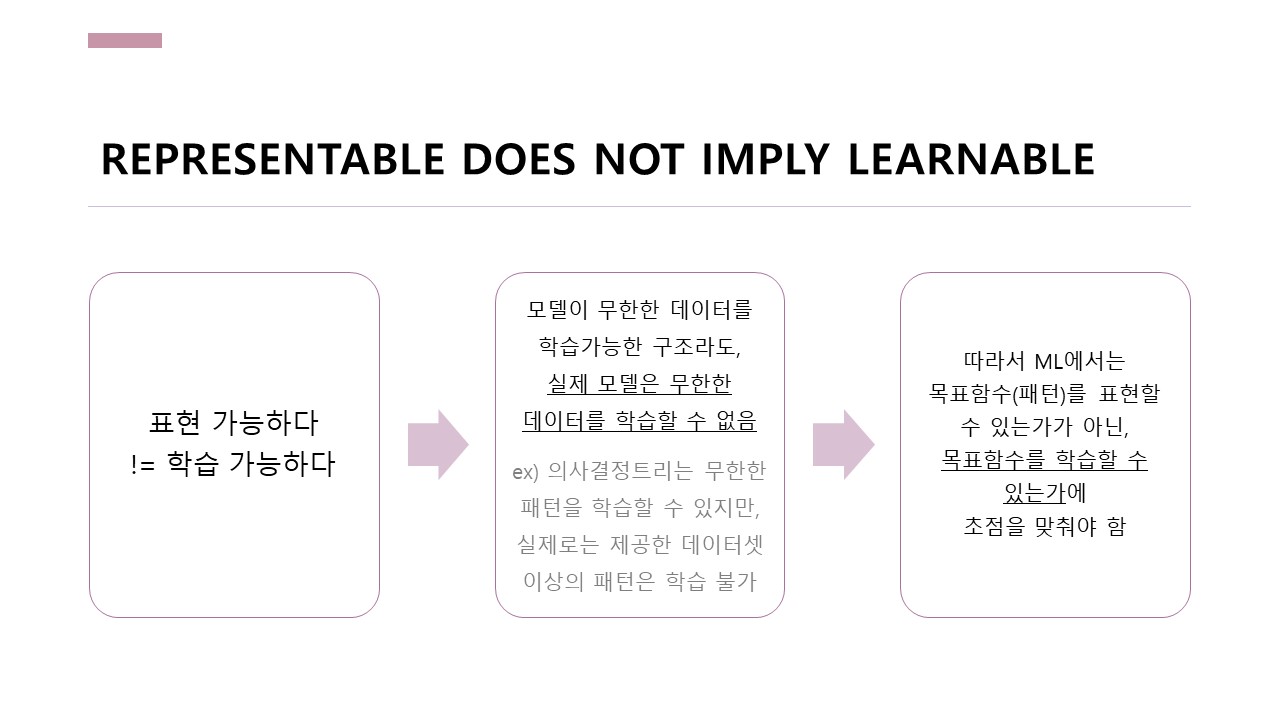
모델이 의사결정트리 같이 무한한 데이터의 패턴을 학습할 수 있는 구조라도, 실제 모델은 제공한 데이터셋 이상의 패턴은 학습할 수 없습니다.
따라서 머신러닝에서는 모델이 패턴을 표현할 수 있는가가 아닌, 패턴을 학습할 수 있는가에 초점을 맞춰야 합니다.
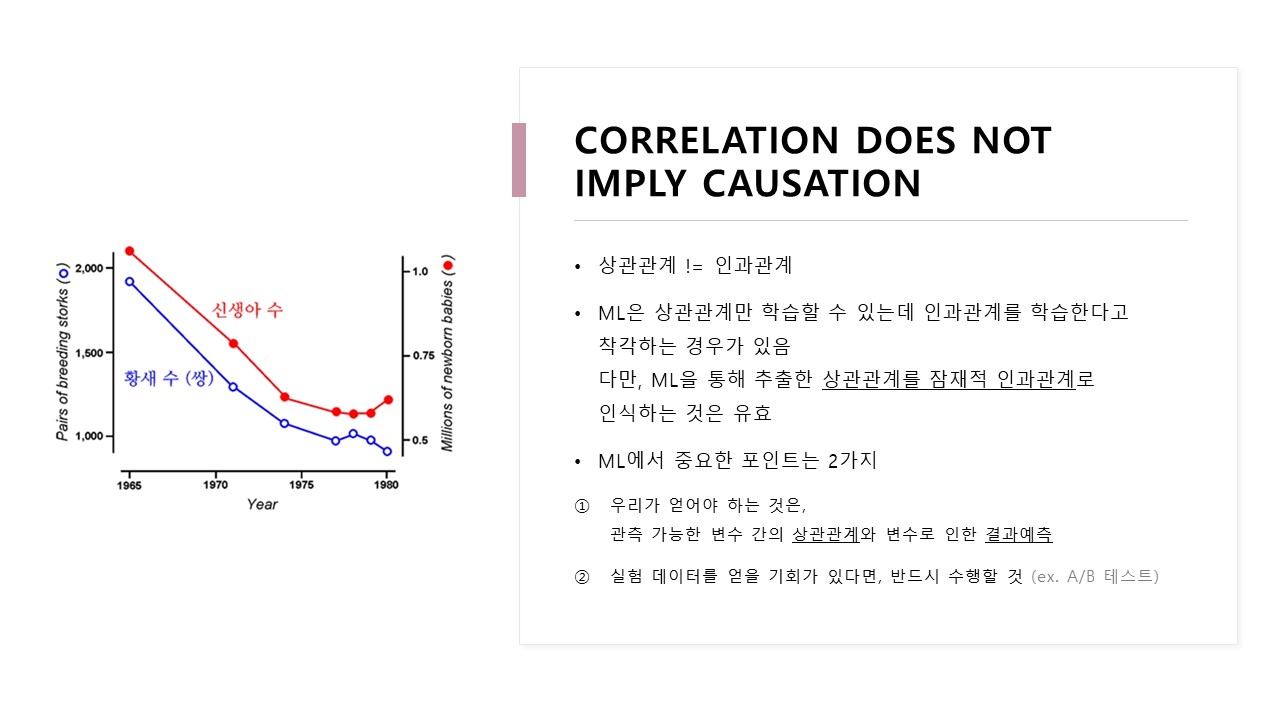
상관관계가 있다고 해서 인과관계가 있다고는 볼 수 없습니다.
오른쪽 사진은 신생아 수와 황새 개체 수에 대한 시계열 그래프입니다.
신생아 수 그래프와 황새 개체 수 그래프는 비슷하게 움직이기에 상관관계가 있지만,
논리적으로 생각했을 때 인과관계가 있다고 볼 수는 없습니다.
마찬가지로 머신러닝 모델은 상관관계만 학습할 수 있는데, 종종 사람들은 머신러닝 모델이 인과관계를 학습한다고 착각하는 경우가 있기에 주의해야 합니다.

지금까지 12가지의 머신러닝에서 필수적인 folk knowledge에 대해 다뤘습니다.
그리고 더 자세한 내용을 알고 싶으면 마스터 알고리즘을 참고하라네요.
위 슬라이드는 인하대학교 빅데이터 학회 IBAS 논문 리뷰 스터디(2023년 5월 26일)에서 사용된 자료입니다.