
[논문 리뷰] 뭐야 내 모델 돌려줘요: ACTIVETHEIFF와 Black-Box Ripper
최근 딥러닝 기술이 대두되고 있는데, 모델을 탈취하는 방식에 관한 주제로 논문 2개를 가져왔습니다.

첫 번째는 AAAI2020에서 발표된 ACTIVETHIEF: Model Extraction Using Active Learning and Unannotated Public Data입니다.
해당 논문에서는 Label이 없는 데이터셋을 이용해 모델을 추출하는 방법을 소개합니다.

두 번째는 NeurIPS 2020에서 발표된 Black-Box Ripper: Copying black-box models using generative evolutionary algorithms입니다.
해당 논문에서는 목표 모델을 이용해 Generator 모델을 만들고, Generator로 학습 데이터를 생성하는 방법을 제안합니다.
Overview

두 논문 모두 모델이 어떤 형태로 구성되었는지, 어떤 학습 데이터를 사용했는지 모르는 상황에서 제한된 API만을 이용해 모델을 복제(Stealing)하는 방법을 설명합니다.
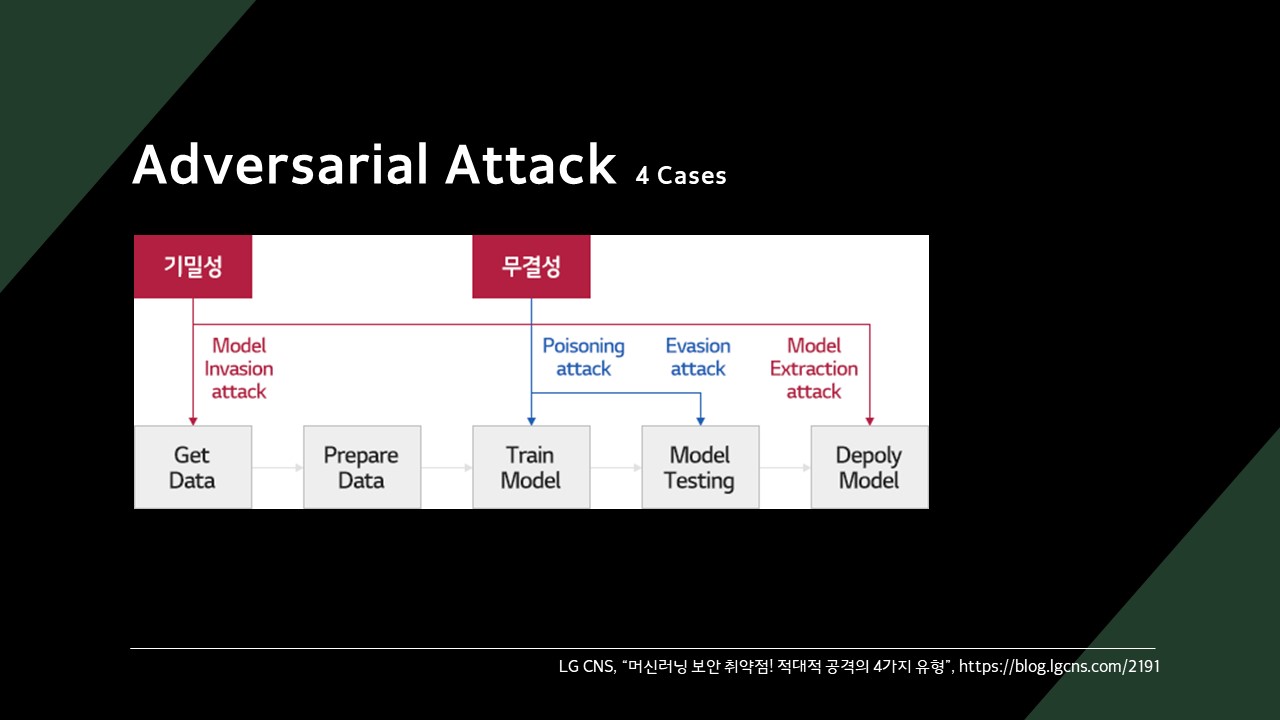
모델을 공격하는 방식은 크게 4가지로 구분할 수 있습니다.
- Invasion Attack
- Poisoning Attack
- Evasion Attack
- Extraction Attack

Invasion Attack은 모델 학습에 사용된 데이터셋을 복원하는 공격 기법입니다.
분류 모델은 주어진 입력에 대한 결과와 신뢰도를 함께 출력하는데, 이 값을 이용해 학습 과정에서 사용한 데이터를 추론하는 방식입니다.

Poisoning Attack은 의도적으로 악의적 학습 데이터를 주입해 모델을 망가뜨리는 공격입니다.

Evasion Attack은 입력 데이터에 최소한의 변조를 가해 분류 모델을 속이는 공격입니다.
Explaining and harnessing adversarial examples에 따르면, 판다 이미지에 노이즈를 섞어 사람한테는 판다로 보이지만 모델은 원숭이로 인식하는 이미지를 생성할 수 있습니다.
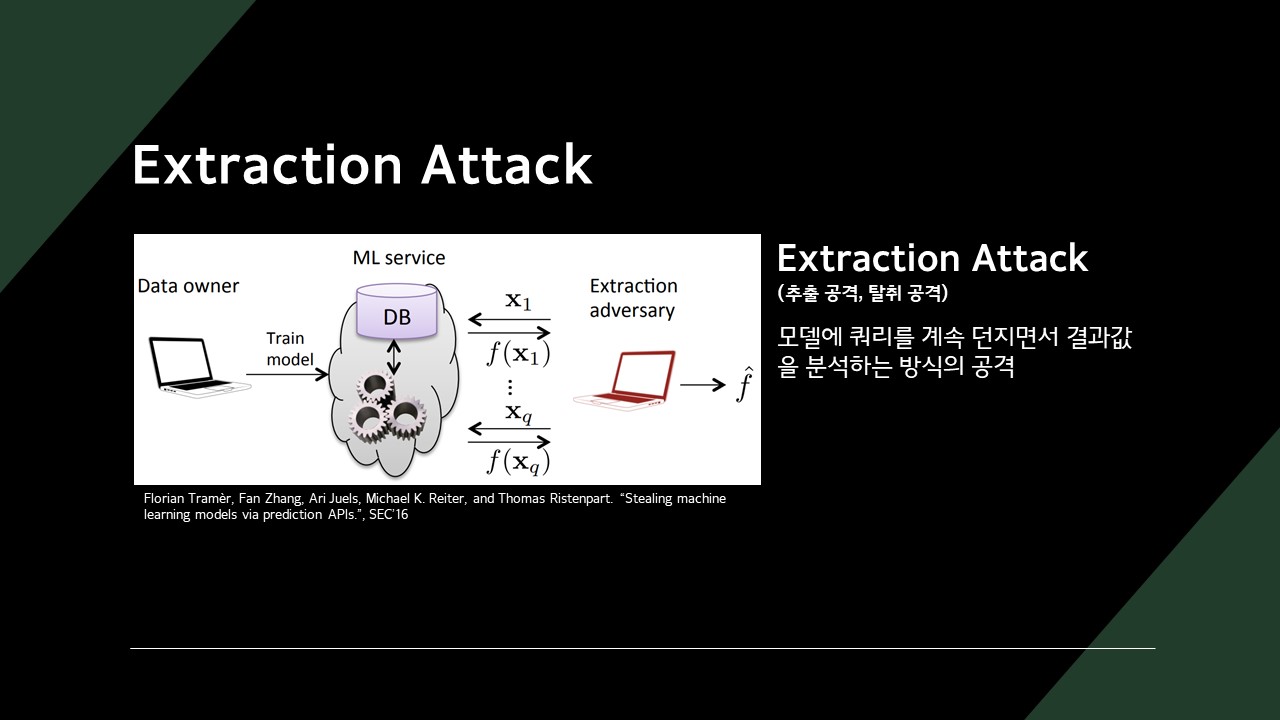
Extraction Attack은 모델에 쿼리를 계속 던지면서 결괏값을 분석하는 방식의 공격합니다.
Extraction Attack의 타겟은 Graybox 모델과 Blackbox 모델이 있는데, 각각 공격 방법이 다릅니다.

Graybox는 목표 모델에 대한 사전지식이 있는 모델을 말합니다.
Stealing machine learning models via prediction APIs: 모델에게 반복적으로 데이터를 보내며 결괏값의 변화를 관찰Practical Black-Box Attacks against Machine Learning: 결정 경계선(Decision boundary) 근처의 데이터가 많은 정보를 내포하고 있다는 점을 활용

BlackBox는 목표 모델에 대한 사전지식이 없는 모델을 말합니다.
스터디에서는 BlackBox 모델을 추출하는 논문 중 ACTIVETHEIFF와 Black-Box Ripper가 어떻게 동작하는지 알아볼 것입니다.
ACTIVETHIEF
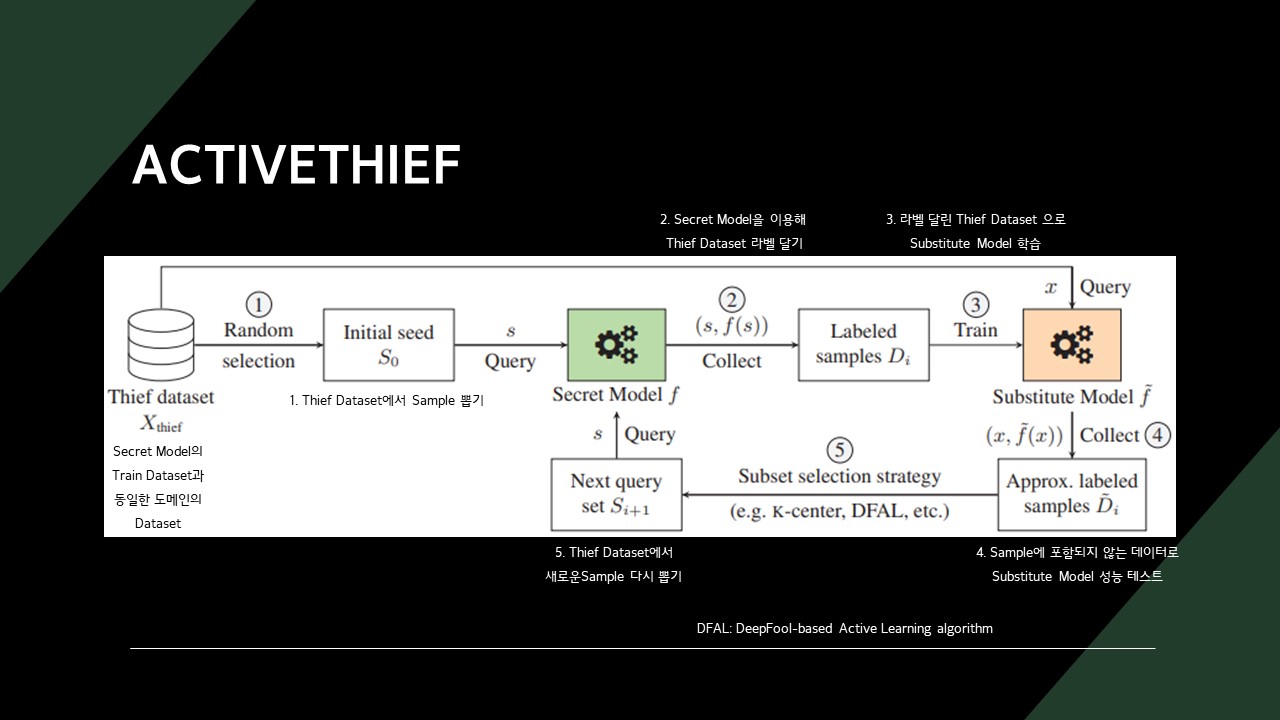
ACTIVETHEIFF는 공격 목표 모델과 동일한 도메인의 데이터셋(Thief Dataset)과 Subset selection strategies을 이용해 모델을 추출합니다.
Thief Dataset은 Label이 없어도 됩니다.
- Thief Dataset에서 Sample을 뽑습니다.
- 목표 모델을 이용해 Sample에 라벨을 만들어 줍니다.
- 라벨 달린 Sample로 새로운 모델을 학습시킵니다.
- Sample에 포함되지 않는 데이터로 학습시킨 새로운 모델의 성능을 테스트합니다.
- Thief Dataset에서 새로운 Sample을 다시 뽑습니다.

Subset selection strategies에는 아래 4가지 방법이 있었습니다.
- Random
- Uncertainty: 학습이 덜 된 데이터 선택
- k-center: 배웠던 데이터와 가장 다른 데이터를 선택
- DFAL: 목표 모델과 새로운 모델의 출력이 다른 데이터 중에 학습한 데이터와 비슷한 데이터 선택(=틀린 문제 중 비슷한 유형 다시 풀기)
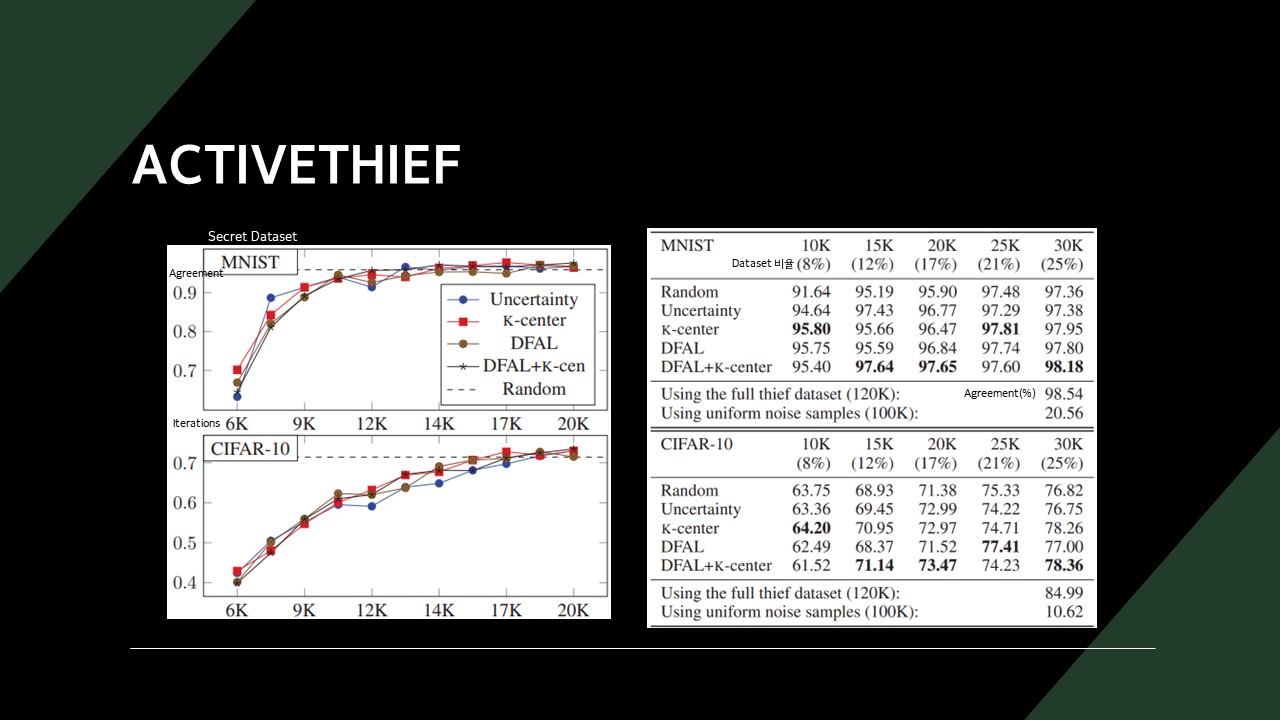
k-center 계열 방식을 선택했을 때 정확도(Argreement)가 가장 높아지는 것을 확인할 수 있습니다.
Black-Box Ripper
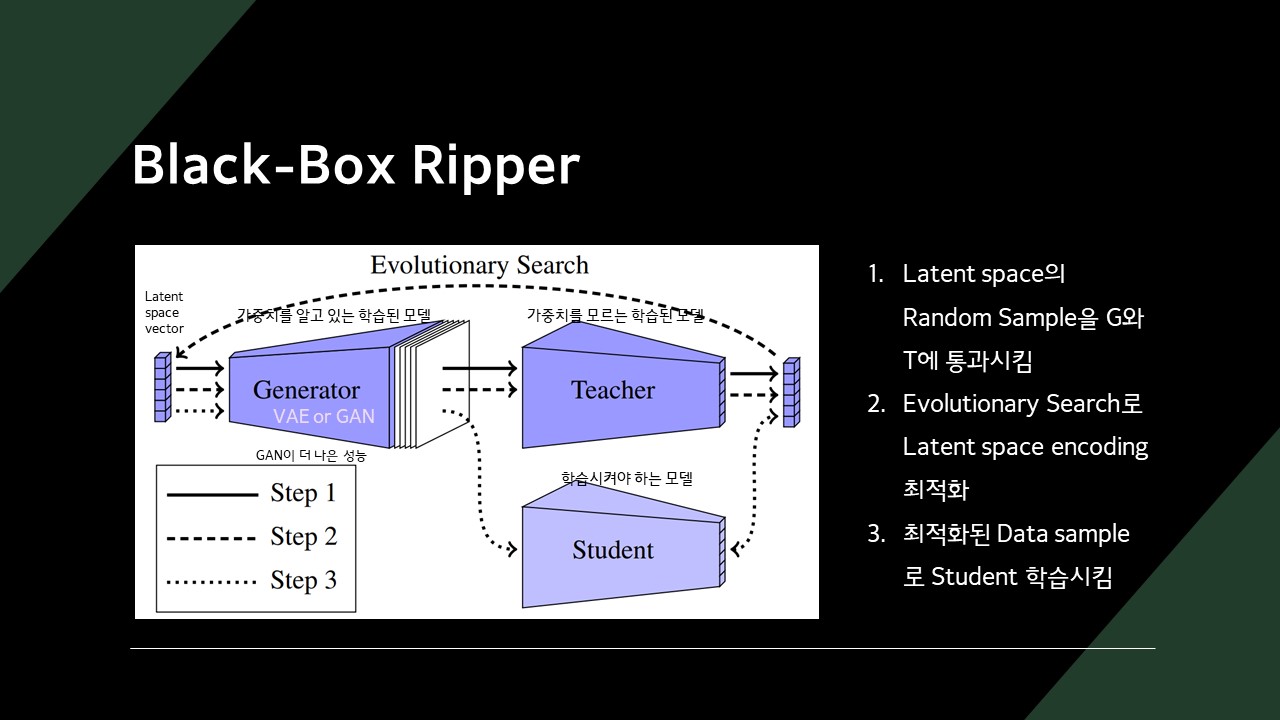
Black-Box Ripper는 VAE나 GAN을 이용해 Latent space vector로부터 학습 데이터를 만들어 냅니다.

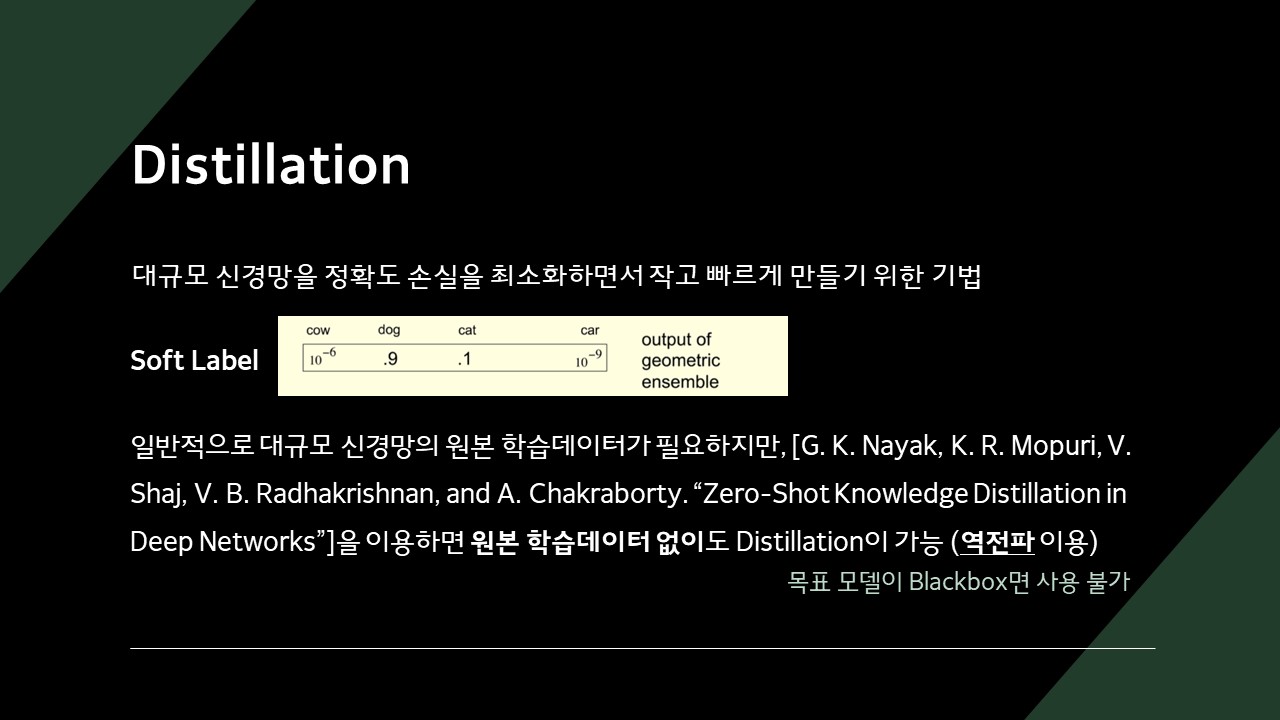
Black-Box Ripper의 비교 대상 방법론으로는 Knockoff Net과 Zero-Shot Knowledge Distillation이 있습니다.
참고: Knockoff Net: 랜덤한 입력으로 다른 모델을 모방할 수 있을까?
Distillation은 모델을 압축하는 기법인데, 크기가 큰 모델을 작은 모델에 전이(Transfer)시키는 원리입니다.
Zero-Shot Knowledge Distillation은 일반적인 Distillation과 달리, 원본 학습데이터 없이 Distillation을 시키는 방법을 제시합니다.
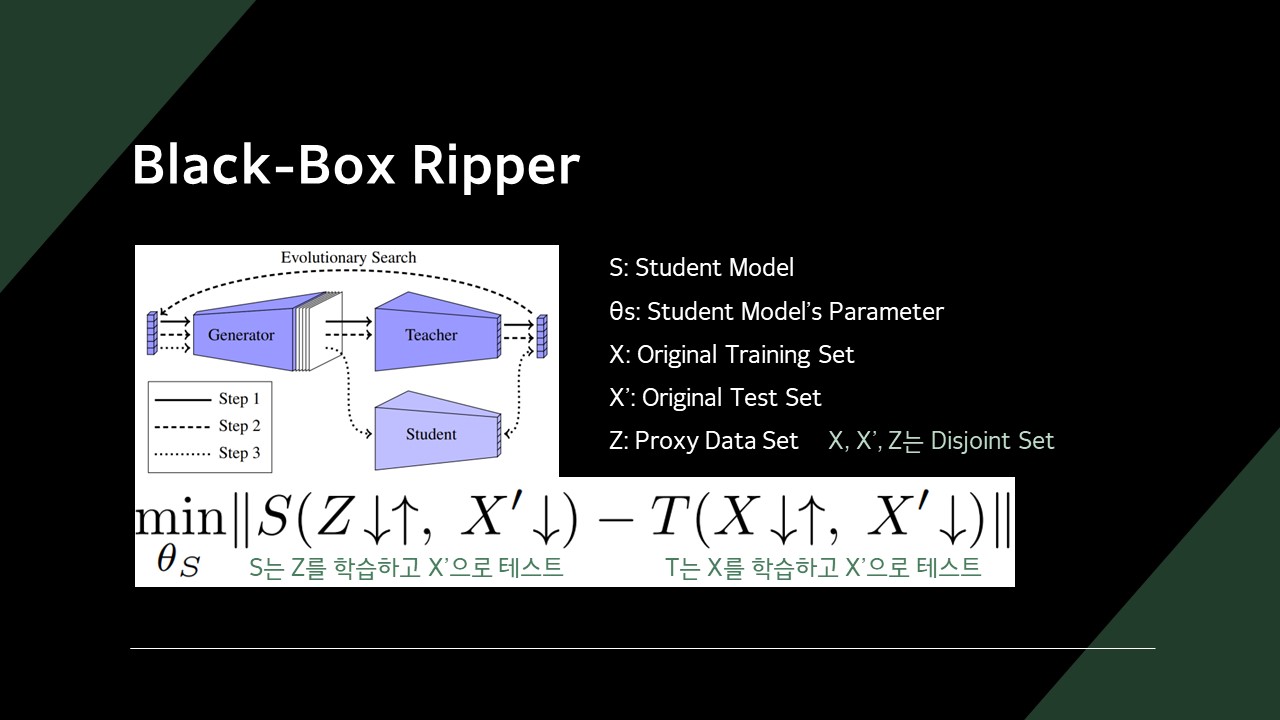
수식에서의 화살표는 모델에서의 순전파(Forward Propagation)와 역전파(Back Propagation)를 의미합니다.
Black-Box Ripper는 미리 학습 데이터를 준비하지 않아도, Generator를 이용해 Proxy Dataset Z를 만들어 Student 모델을 학습시킵니다.



Teacher 모델은 공격 대상이 되는 모델입니다.
우리가 만들어야 하는 것은 Generator와 Student 모델입니다.
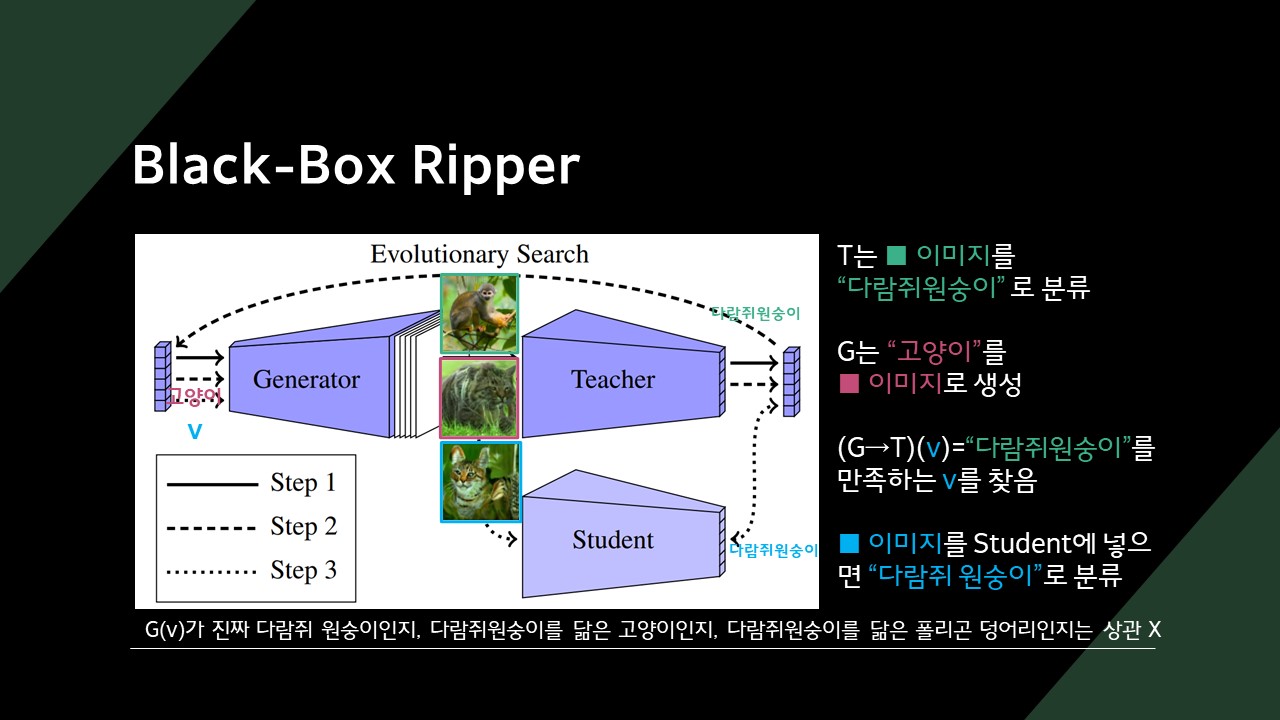
Evolutionary Search 알고리즘은 Generator로 원하는 도메인의 이미지를 만들어 낼 수 있는 Latent vector를 찾아냅니다.
찾아낸 Latent vector를 Generator에 넣게 되면 라벨이 달린 학습 데이터셋이 만들어지게 됩니다.
학습 데이터셋이 만들어졌으니, 이제 Student 모델을 학습시키면 됩니다.
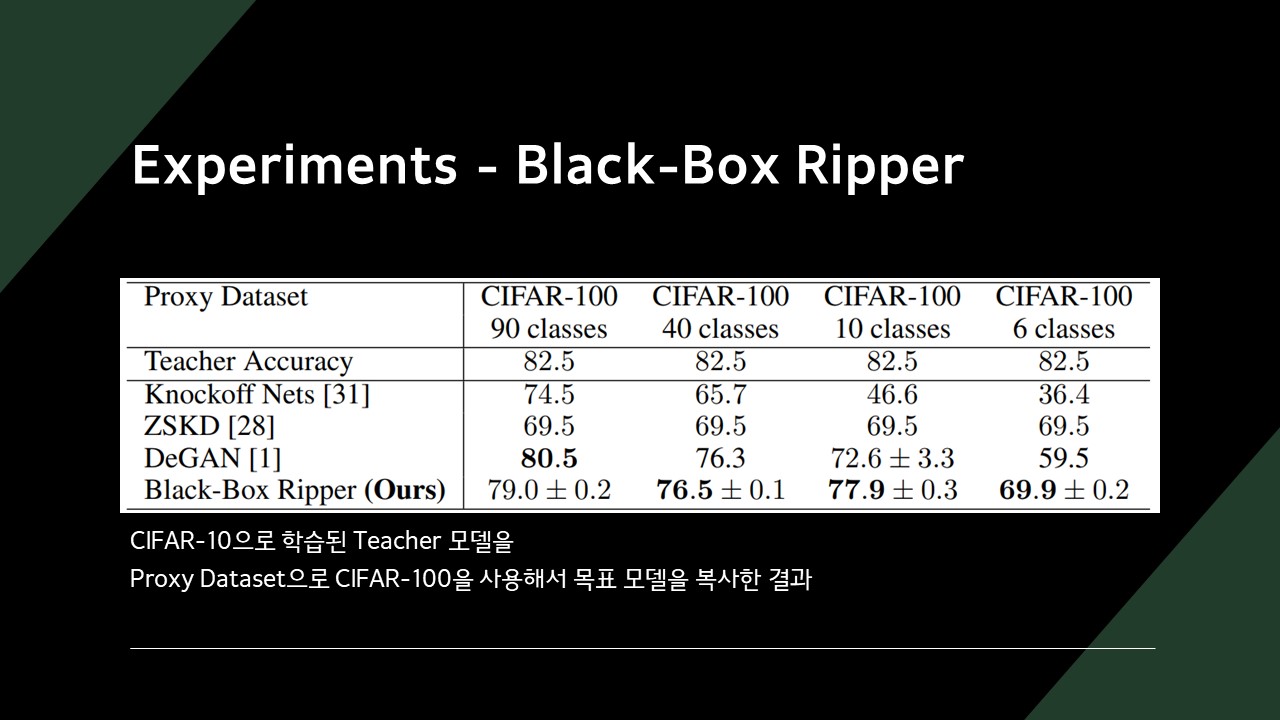
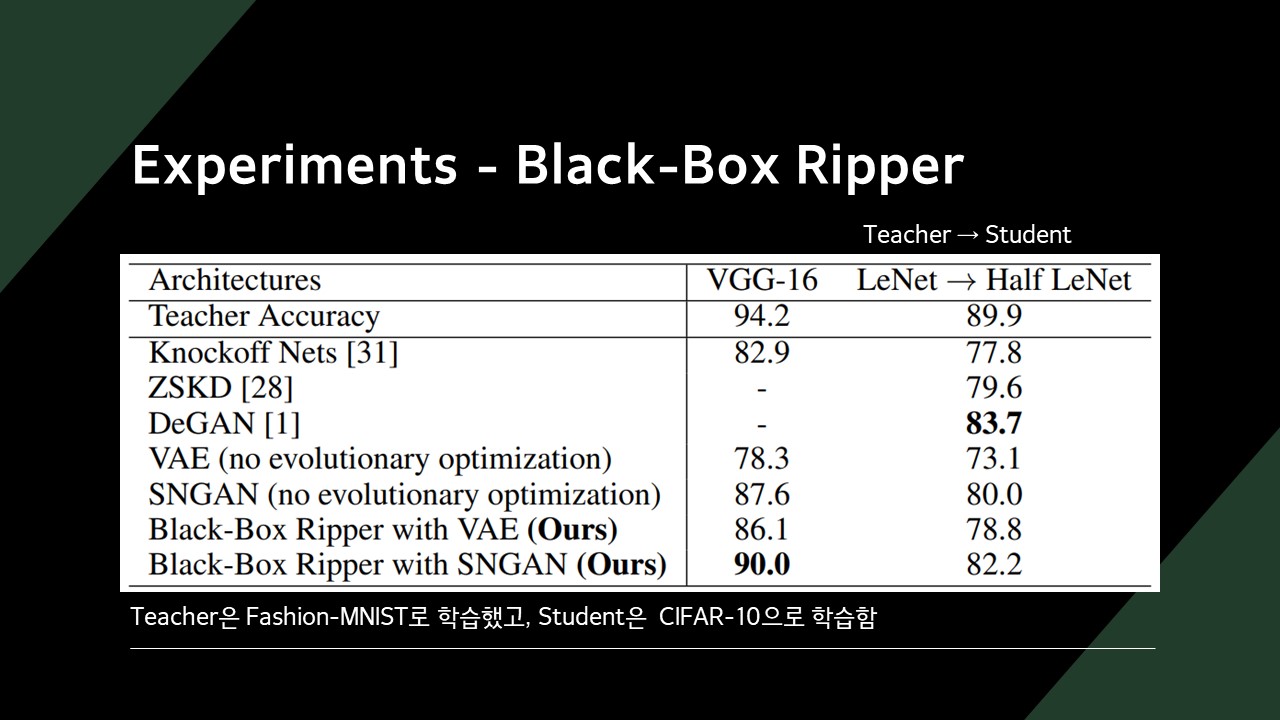
목표 모델의 정확도가 80% 초반일 때, 복사한 모델의 정확도 70% 수준인 것을 확인할 수 있었습니다.
기존의 Knockoff Net이나 ZSKD(Zero-Shot Knowledge Distillation)보다 높은 정확도를 보이는 것을 확인할 수 있습니다.
일부 데이터에선 DeGAN에 밀리는 것도 확인할 수 있었습니다.

Generator 결과만 따로 뽑았을 때, 점점 Label과 비슷한 느낌의 이미지를 만들어 내는 것을 확인할 수 있었습니다.
Conclusion


두 논문 모두 Blackbox 모델을 탈취하는 방법을 제시했고 복제된 모델의 정확도도 상당히 높게 나왔습니다.
최근 AI 서비스의 상당수가 API를 통해 서비스를 제공하는데,
외부에 API만 열어뒀더라도 핵심 모델이 탈취당할 수 있다는 것이 두 논문의 요점입니다.
모델 탈취를 어렵게 하기 위해 출력에 노이즈를 섞는 PRADA 같은 방식도 제시되었고,
모델 탈취를 확인하기 위해 식별 값을 넣는 IPGuard도 제시되었으나,
현재로선 근본적인 해결 방법이 되지 않기에 추가적인 연구가 필요하다는 것이 결론입니다.
위 슬라이드는 인하대학교 빅데이터 학회 IBAS 논문 리뷰 스터디(2022년 11월 11일)에서 사용된 자료입니다.