
[논문 리뷰] 난 몰랐어 CNN이 이리 다채로운지: DeepLab의 Atrous CNN
Atrous CNN: kernel 픽셀 간의 간격을 두어 kernel size를 늘리지 않고 시야(Receptive field)를 키우는 기법

DeepLab은 Google에서 개발한 Sementic Image Segmentation 모델이며, 2015년에 처음 발표되었습니다.

첫 논문의 제목은 DeepLab이 아니라 Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs으로, DeepLab V1이 논문의 별명입니다.
DeepLab V2라는 별명이 붙은 이유는 후속 논문의 이름이 DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs이기 때문에, 원 논문을 DeepLab V1이라 부르고 그 후속 논문을 DeepLab V2라고 부르게 되었습니다.
DeepLab V1은 2015년 ICLR에서 발표되었습니다.
ICLR은 ML 탑티어 학회 중 하나입니다.
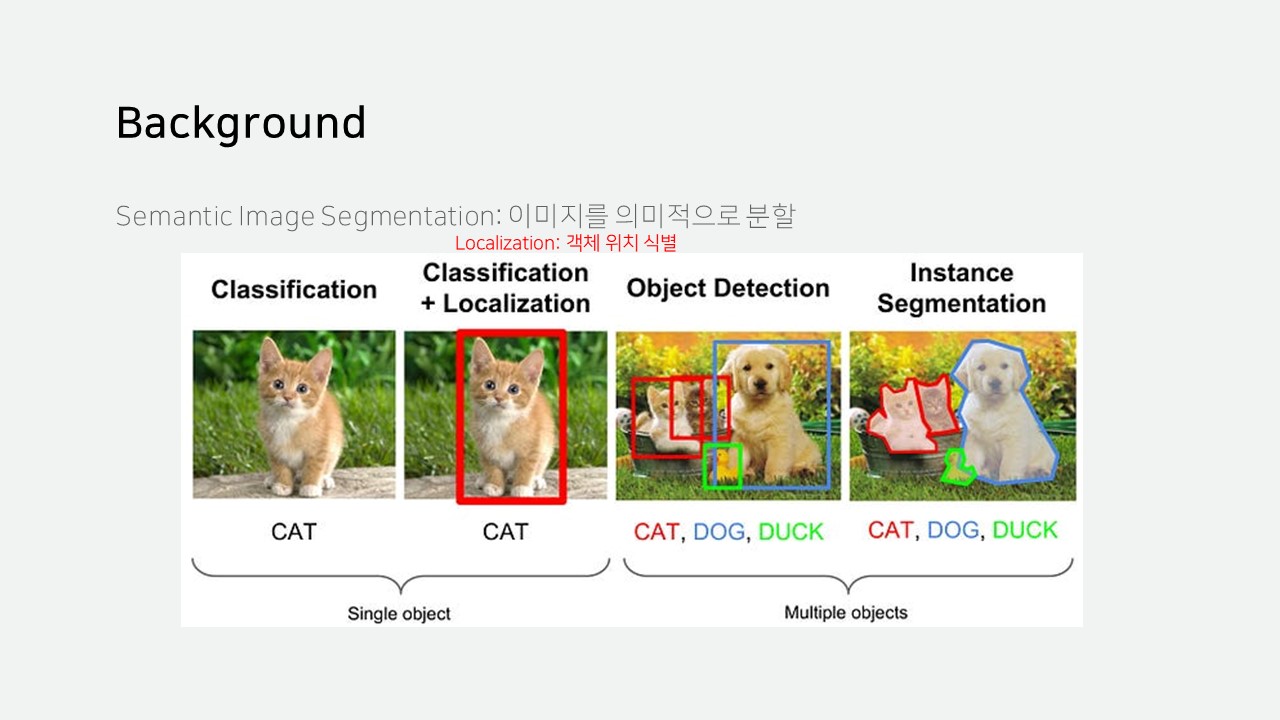
Sementic Image Segmentation은 이미지를 의미적으로 분할하는 것을 말합니다.
Classification은 단일 객체 식별
Localization은 객체의 위치를 사각형으로 표시
Object Dectection은 여러 객체 식별 및 위치 표시
Image Segmentation은 여러 객체 식별 및 픽셀 단위의 위치 표시를 의미합니다.

Image Segmentation은 또 2가지로 나뉘는데,
Semantic Segmentation은 같은 종류의 사물을 서로 구분하지 않고,
Instance Segmentation은 같은 종류의 사물도 독립적인 객체인지 식별합니다.
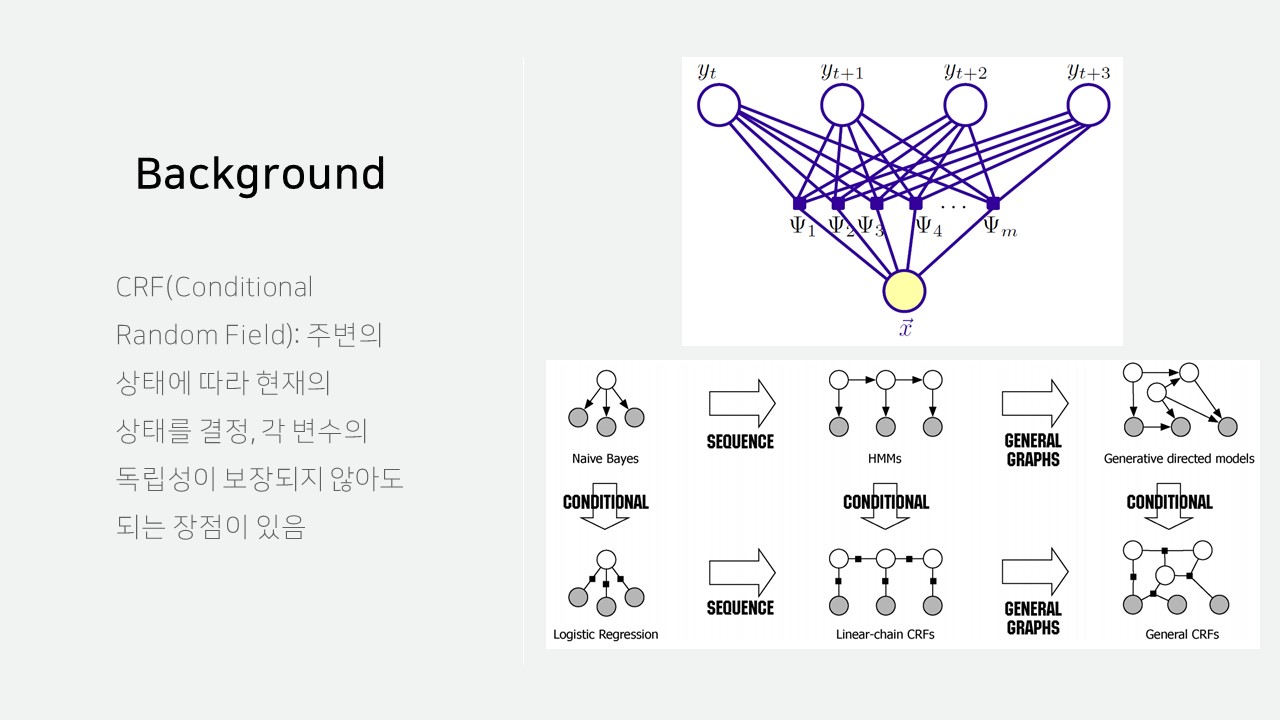
CRF는 주변의 상태에 따라 현재의 상태를 결정하는 알고리즘으로, 각 변수의 독립성이 보장되지 않아도 되는 장점이 있습니다.

CNN은 이미지 분류나 객체 인식과 같은 작업에서 좋은 성능을 보여왔습니다.
하지만 CNN만으로는 Segmentation이 잘되지 않아, CNN과 CRF를 결합하여 문제를 해결했습니다.
또한, Hole algorithm을 도입하여 빠른 CNN 계산을 가능하게 했습니다.

CNN의 불변성(Invariance)는 데이터의 작은 변화를 무시하는 특징으로, 객체의 위치보다는 패턴에 집중할 수 있게 합니다.
따라서 CNN만 이용하면 객체의 정확한 위치를 검출하기 어렵습니다.
그래서 CRF로 후처리를 해 정확한 객체 경계를 뽑아낼 수 있게 했습니다.
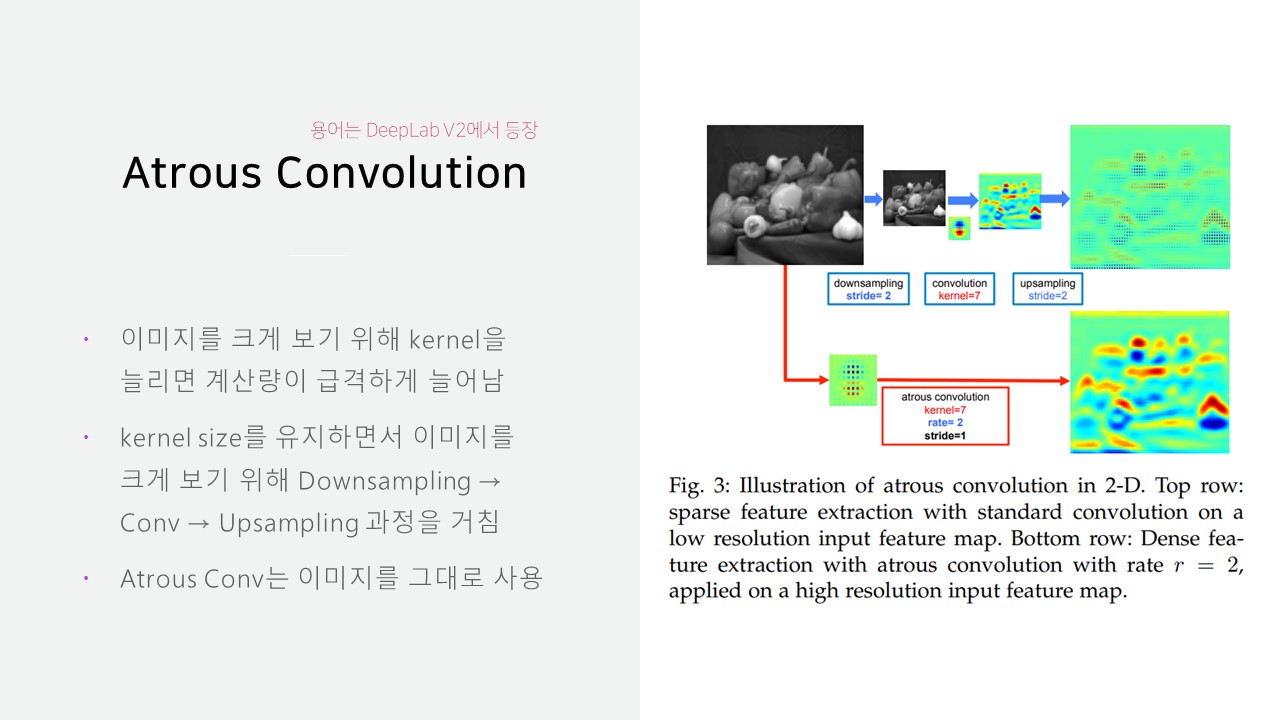
CNN에는 성능을 위해 max-pooling과 downsampling으로 데이터의 크기를 줄이게 되는데 여기서 많은 위치 정보가 소실됩니다.
많은 위치 정보가 소실되는 문제는 Hole algorithm을 통해 속도와 정확도 둘 다 잡았습니다.
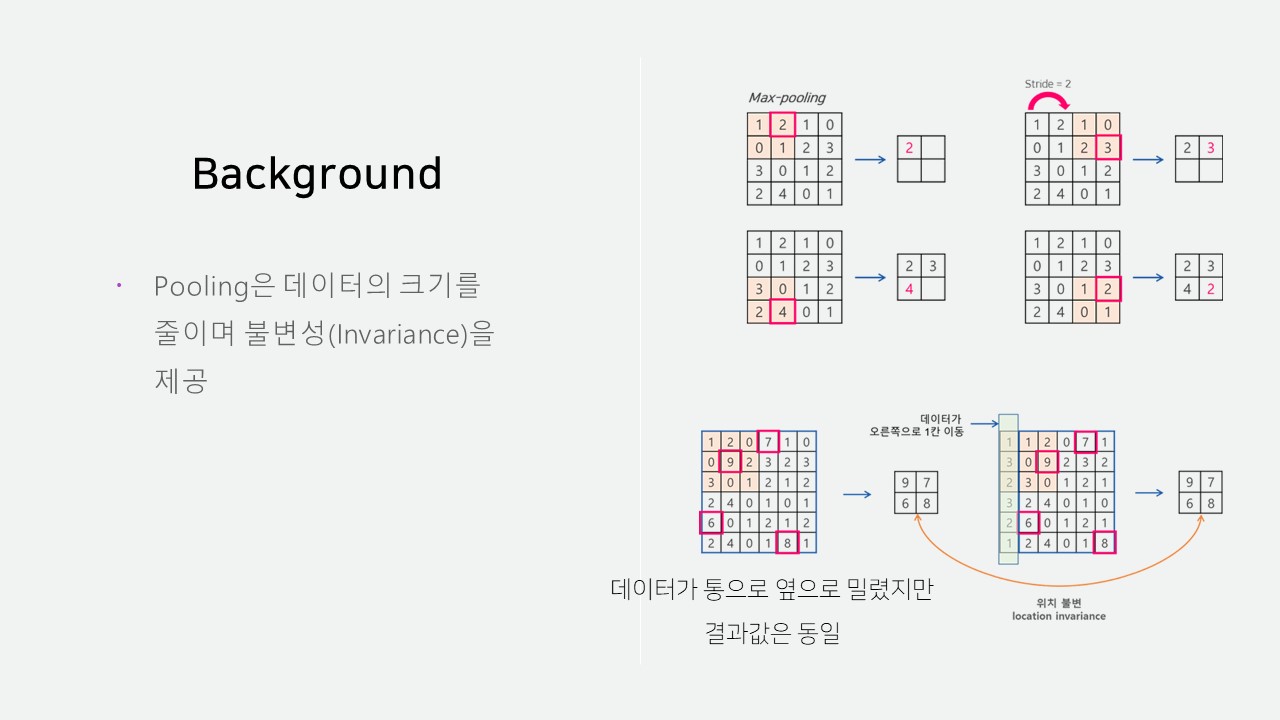
CNN의 불변성(Invariance)에 대한 추가적인 설명을 해드리자면, 오른쪽 그림과 같이 max-pooling과 함께 사용되어 원본 데이터가 변하더라도 결괏값은 동일하게 나오는 것을 확인할 수 있습니다.
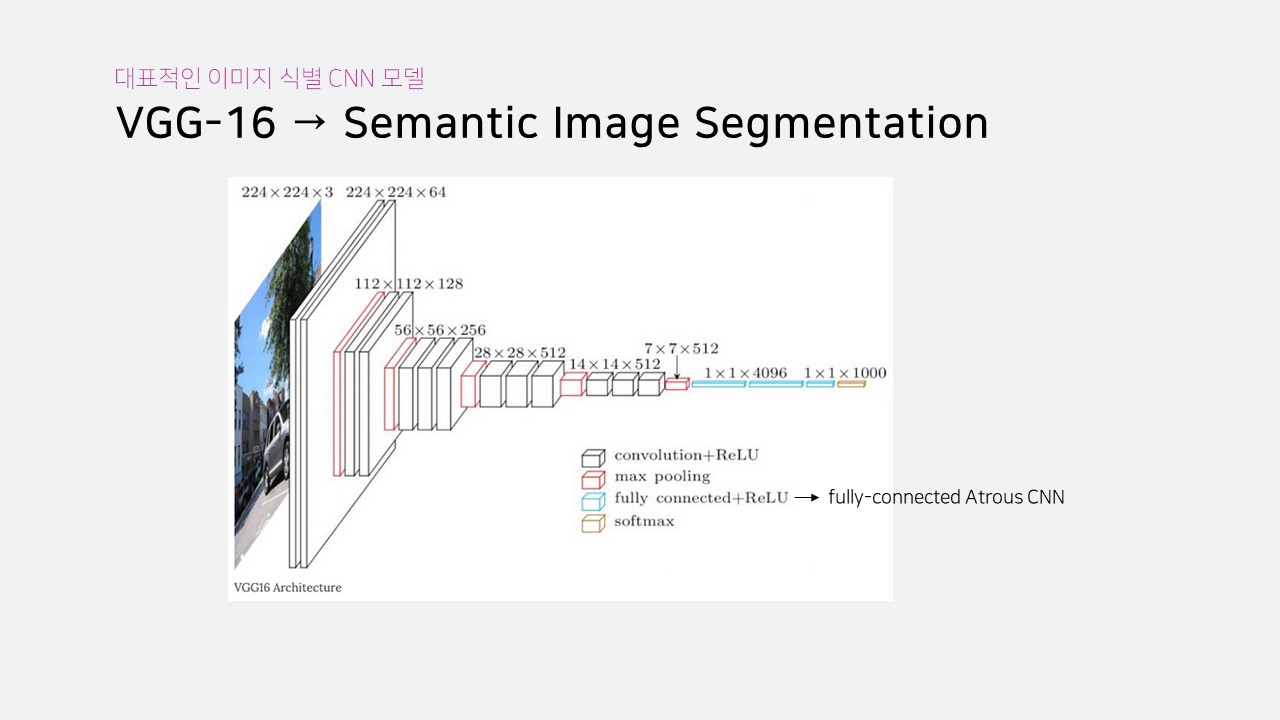
DeepLab은 VGG-16 모델을 수정하여 Sementic Segmentation을 구현했다고 합니다.
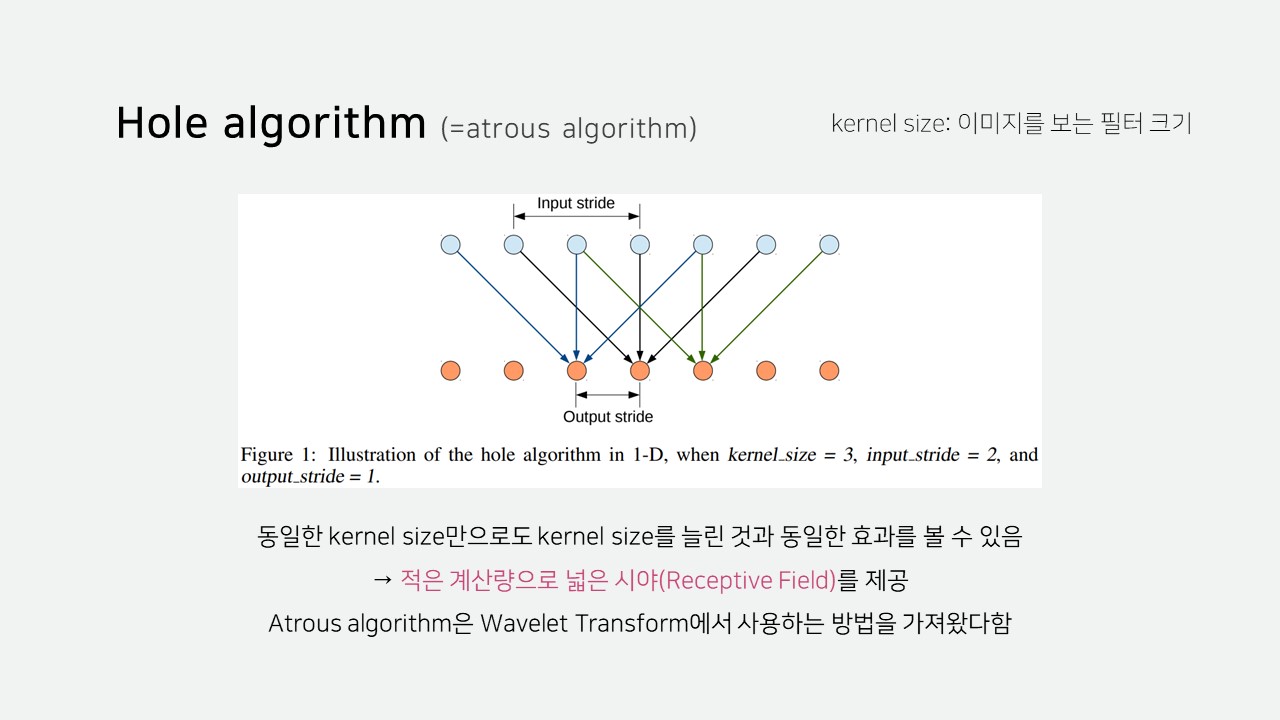
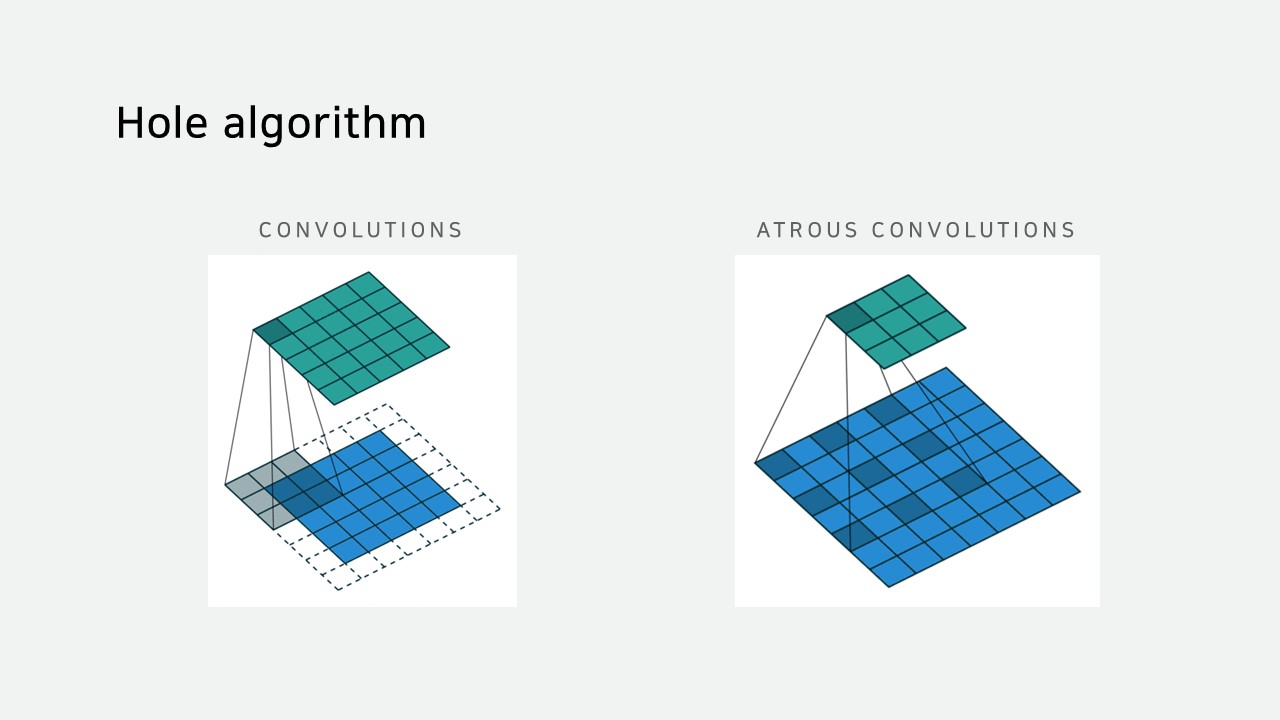
Hole algorithm은 입력을 한 칸씩 띄워 받아들입니다.
따라서 동일한 kernel size만으로 더 넓은 시야를 제공합니다.
적은 계산량으로 넓은 시야를 볼 수 있기 때문에 이미지를 작게 만들 필요가 없어 위치 정보도 그만큼 덜 손실됩니다.



CNN만으로는 객체의 경계를 명확히 구분하기 어렵기 때문에 CRF로 후처리했습니다.
다만, 일반적인 CRF는 객체의 경계를 부드럽게 하는 알고리즘이기 때문에 Fully-connected CRF를 사용해야 합니다.
Fully-connected CRF는 주변 픽셀만 고려하는 것이 아닌, 이미지의 모든 픽셀을 고려하여 현재 픽셀의 상태를 결정합니다.
Fully-connected CRF는 DenseCRF라고도 불린다고 합니다.
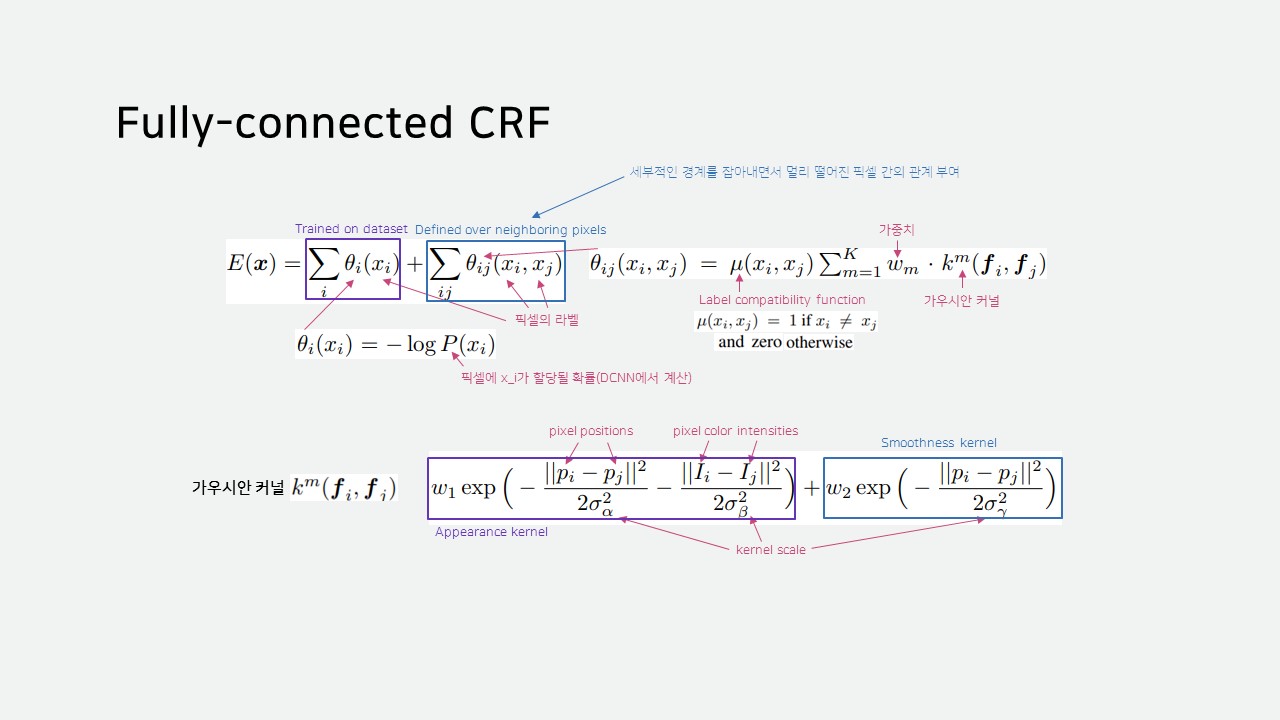
이미지의 모든 픽셀을 봐야 하므로 당연히 계산량도 많습니다.
Fully-connected CRF의 계산량을 줄이기 위해 Mean Field Approximation 기법을 사용했다고 합니다.
참고: Efficient Inference in Fully Connected CRFs with Gaussian Edge Potentials
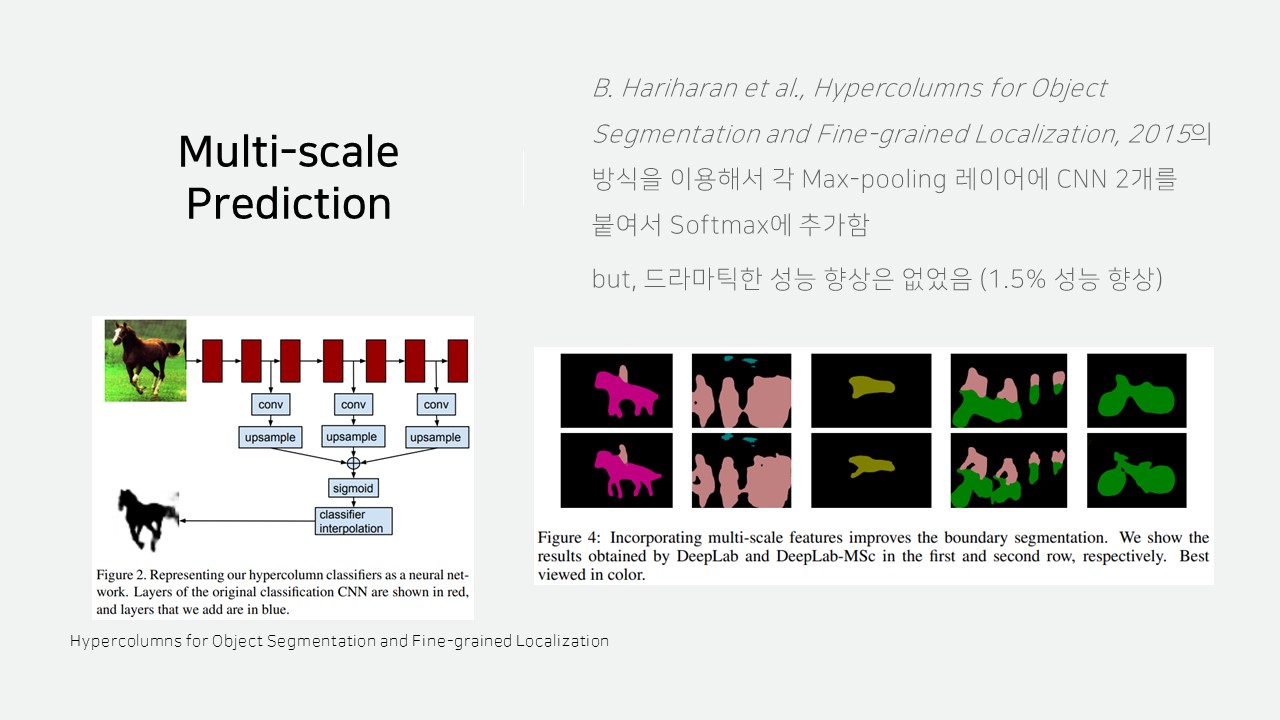
추가적인 정확도 향상을 위해 레이어 중간에서 크기가 다른 데이터를 뽑아와 CNN에 적용해 최종값에 반영하는 Multi-scale Prediction도 적용되었습니다.
하지만, 드라마틱한 성능 향상은 없었다고 합니다.


CRF와 Multi-scale Prediction 모두 적용한 모델이 가장 나은 성능을 보여줬습니다.
또한, FCN과 비교했을 때 객체의 경계를 디테일하게 잡아내고 TTI-Zoomout과 비교했을 때 잘못된 경계를 잡는 비율이 적은 것을 확인할 수 있습니다.
TTI-Zoomout 결과에서 경계가 자글자글한 이유는 Superpixel로 나누는 과정에서 경계가 제대로 나눠지지 않았기 때문이라고 생각합니다.


Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs는 첫 번째 논문으로, V3+까지의 후속 논문이 존재합니다.
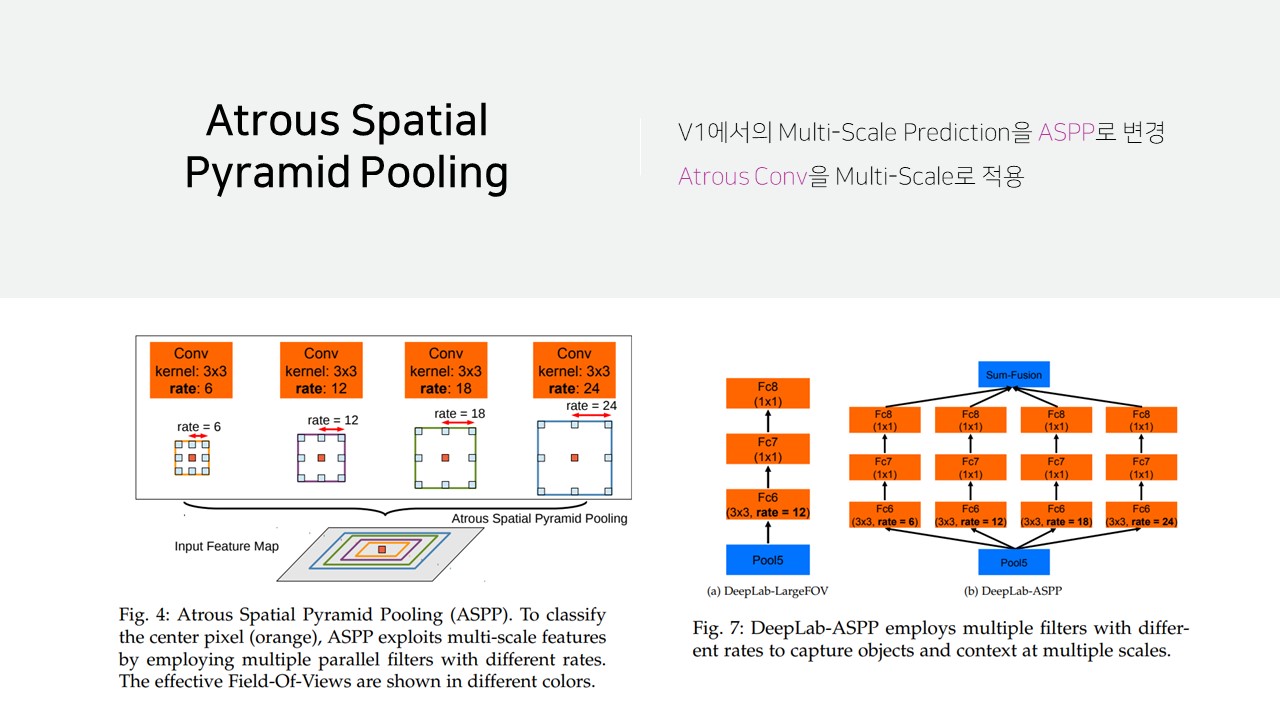
V2에 도입된 Atrous Spatial Pyramid Pooling(ASPP)는 Multi-scale Prediction과 동일한 방식인데 CNN이 Atrous CNN으로 변경한 것입니다.
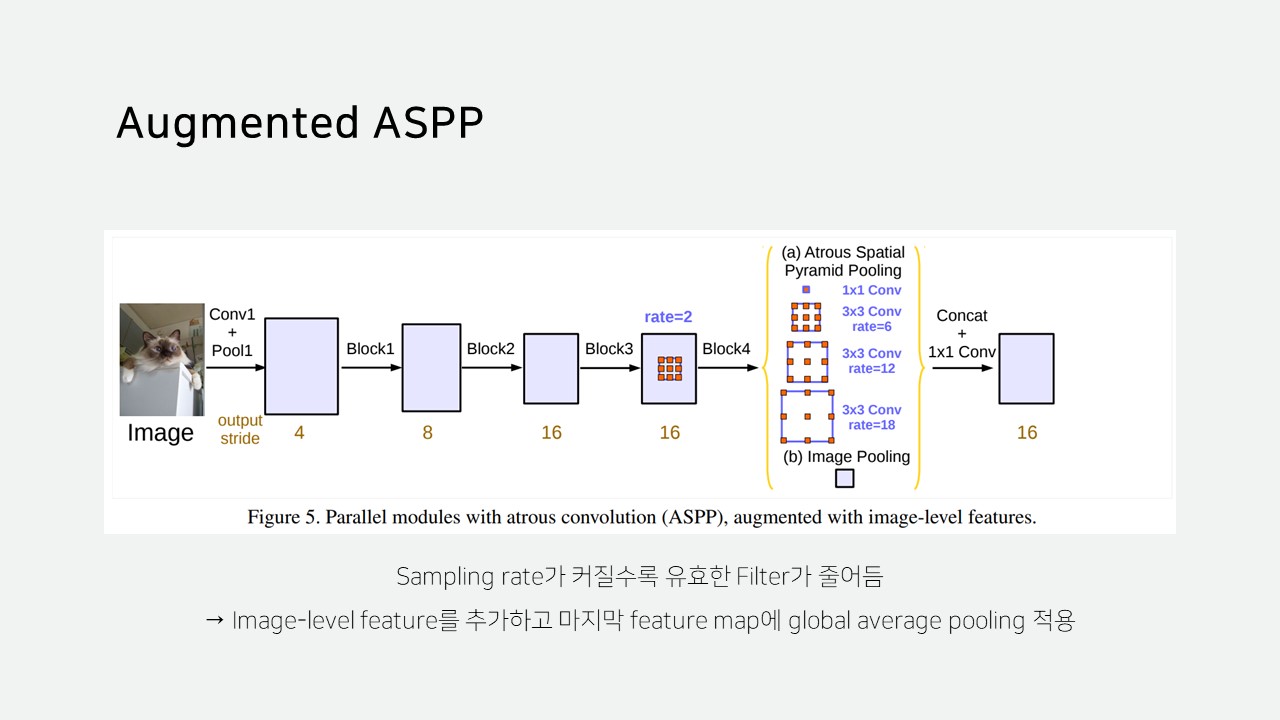
V3의 Augmented ASPP는 Image-level feature를 추가하여 기존 ASPP에서 Sampling rate가 커질수록 유효한 filter가 줄어드는 문제를 해결하고자 했습니다.
V3부터는 CRF 없이도 좋은 성능이 나와 CRF가 제거되었다고 합니다.
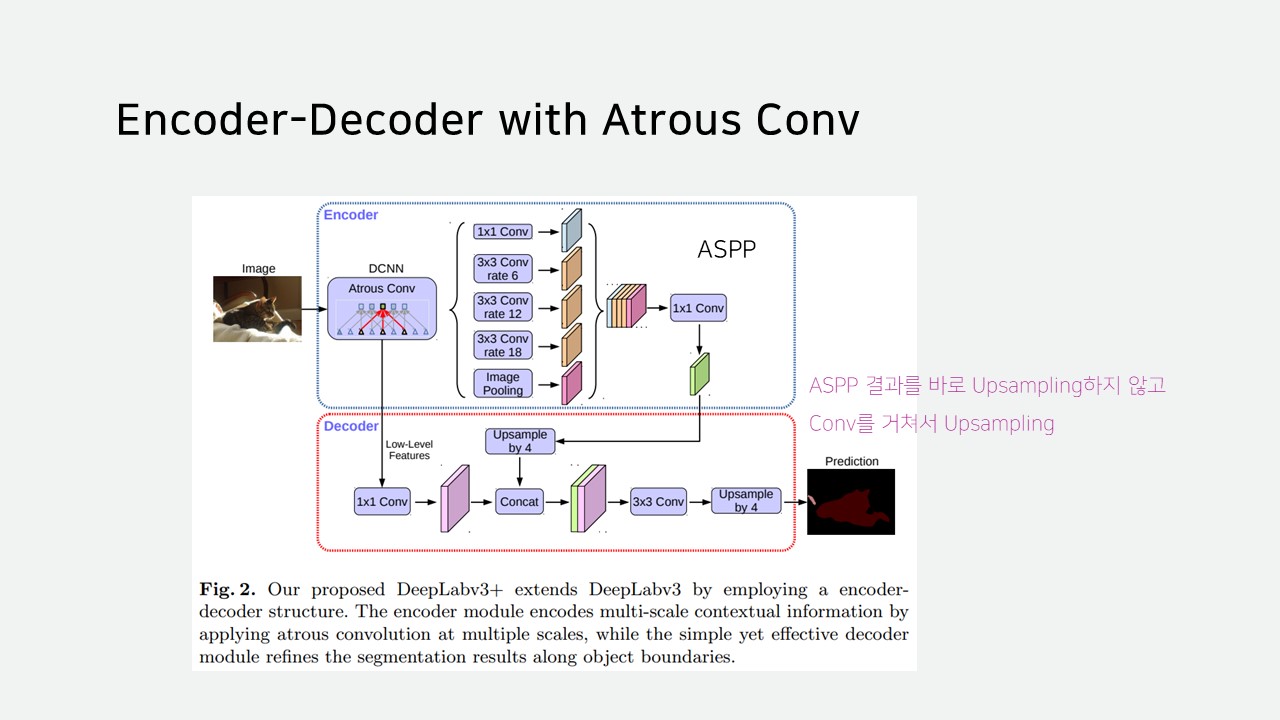
V3+에는 후처리 과정을 Encoder-Decoder 과정으로 나누어 ASPP 결과를 바로 Upsampling하지 않고, Encoder에서 가져온 값과 합쳐서 Upsampling합니다.
위 슬라이드는 인하대학교 빅데이터 학회 IBAS 논문 리뷰 스터디(2023년 3월 31일)에서 사용된 자료입니다.
참고: Semantic segmentation과 Instance segmentation의 차이
참고: Semantic Segmentation (FCN, Fully Convolutional Network)
참고: An Introduction to different Types of Convolutions in Deep Learning